これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Kubernetesブログ
- SIG Releaseスポットライト(リリース・チーム・サブプロジェクト)
- フォレンジックコンテナ分析
- Kubernetes 1.26: PodDisruptionBudgetによって保護された不健全なPodに対する退避ポリシー
- Kubernetesにおけるフォレンジックコンテナチェックポイント処理
- 更新: dockershimの削除に関するFAQ
- Don't Panic: Kubernetes and Docker
SIG Releaseスポットライト(リリース・チーム・サブプロジェクト)
筆者: Nitish Kumar
リリース・スペシャル・インタレスト・グループ(SIG Release)は、Kubernetesが4ヶ月ごとに最先端の機能とバグ修正でその刃を研ぐ場所です。Kubernetesのような大きなプロジェクトが、新バージョンをリリースするまでのタイムラインをどのように効率的に管理しているのか、またリリースチームの内部はどのようになっているのか、考えたことはありますか?このような疑問に興味がある方、もっと知りたい方、SIG Releaseの仕事に関わりたい方は、ぜひ読んでみてください!
SIG ReleaseはKubernetesの開発と進化において重要な役割を担っています。その主な責任は、Kubernetesの新バージョンのリリースプロセスを管理することです。通常3〜4ヶ月ごとの定期的なリリースサイクルで運営されています。このサイクルの間、Kubernetesリリースチームは他のSIGやコントリビューターと密接に連携し、円滑でうまく調整されたリリースを保証します。これには、リリーススケジュールの計画、コードフリーズとテストフェーズの期限の設定、バイナリ、ドキュメント、リリースノートなどのリリース成果物の作成が含まれます。
さらに読み進める前に、SIG Releaseにはリリース・エンジニアリングとリリース・チームという2つのサブプロジェクトがあることに注意してください。
このブログ記事では、Nitish KumarがSIG Releaseのテクニカル・リーダーであるVerónica López (PlanetScale)にインタビューし、Release Teamサブプロジェクトにスポットライトを当て、リリース・プロセスがどのように見えるか、そして参加する方法について説明します。
-
最初の計画から最終的なリリースまで、Kubernetesの新バージョンの典型的なリリースプロセスはどのようなものですか?スムーズなリリースを保証するために使用している特定の方法論やツールはありますか?
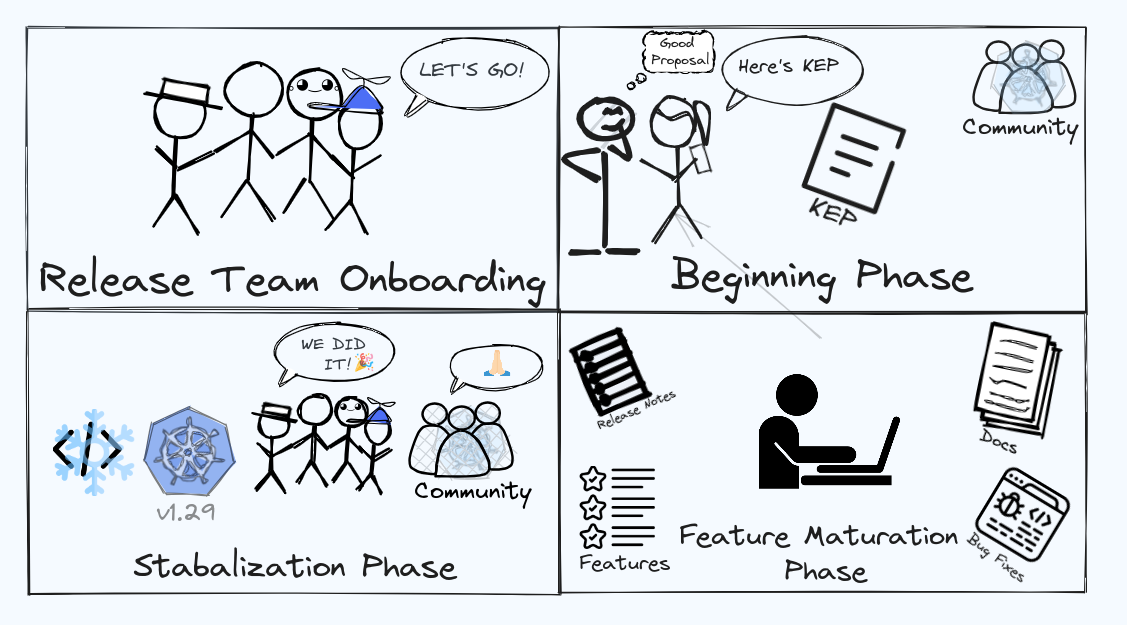
Kubernetesの新バージョンのリリースプロセスは、十分に構造化されたコミュニティ主導の取り組みです。私たちが従う特定の方法論やツールはありませんが、物事を整理しておくための一連の手順を記載したカレンダーはあります。完全なリリースプロセスは次のようになります:
-
リリースチームの立ち上げ: 新しいリリースのさまざまなコンポーネントの管理を担当するKubernetesコミュニティのボランティアを含むリリースチームの結成から始めます。これは通常、前のリリースが終了する前に行われます。チームが結成されると、リリースチームリーダーとブランチマネージャーが通常の成果物のカレンダーを提案する間に、新しいメンバーがオンボードされます。例として、SIG Releaseのリポジトリに作成されたv1.29チーム結成のissueを見てください。コントリビューターがリリースチームの一員になるには、通常リリースシャドウプログラムを通りますが、それがSIG Releaseに参加する唯一の方法というわけではありません。
-
初期段階: 各リリースサイクルの最初の数週間で、SIG ReleaseはKubernetes機能強化提案(KEPs)で概説された新機能や機能強化の進捗を熱心に追跡します。これらの機能のすべてがまったく新しいものではありませんが、多くの場合、アルファ段階から始まり、その後ベータ段階に進み、最終的には安定したステータスに到達します。
-
機能の成熟段階: 通常、コミュニティからのフィードバックを集めるため、実験的な新機能を含むアルファ・リリースを2、3回行い、その後、機能がより安定し、バグの修正が中心となるベータ・リリースを2、3回行います。この段階でのユーザーからのフィードバックは非常に重要で、この段階で発生する可能性のあるバグやその他の懸念に対処するために、追加のベータ・リリースを作成しなければならないこともあります。これがクリアされると、実際のリリースの前にリリース候補(RC)を作成します。このサイクルを通じて、リリースノートやユーザーガイドなどのドキュメントの更新や改善に努めます。
-
安定化段階: 新リリースの数週間前にコードフリーズを実施し、この時点以降は新機能の追加を禁止します。メインリリースと並行して、私たちはKubernetesの古い公式サポートバージョンのパッチを毎月作成し続けているので、Kubernetesバージョンのライフサイクルはその後数ヶ月に及ぶと言えます。完全なリリースサイクル全体を通して、リリースノートやユーザーガイドを含むドキュメントの更新と改善に努めます。
-
各リリースで安定性と新機能の導入のバランスをどのように扱っていますか?どのような基準で、どの機能をリリースに含めるかを決定するのですか?
終わりのないミッションですが、重要なのは私たちのプロセスとガイドラインを尊重することだと考えています。私たちのガイドラインは、このプロジェクトに豊富な知識と経験をもたらしてくれるコミュニティの何十人ものメンバーから、何時間にもわたって議論とフィードバックを重ねた結果です。もし厳格なガイドラインがなかったら、私たちの注意を必要とするもっと生産的な議題に時間を使う代わりに、同じ議論を何度も繰り返してしまうでしょう。すべての重要な例外は、チームメンバーの大半の合意を必要とするため、品質を確保することができます。
何がリリースになるかを決定するプロセスは、リリースチームがワークフローを引き継ぐずっと前から始まっています。各SIGと経験豊富なコントリビューターが、機能や変更を含めるかどうかを決定します。その後、リリースチームが、それらの貢献がドキュメント、テスト、後方互換性などの要件を満たしていることを確認し、正式に許可します。同様のプロセスは月例パッチリリースのチェリーピックでも行われ、完全なKEPを必要とするPRや、影響を受けるすべてのブランチを含まない修正は受け入れないという厳しいポリシーがあります。
-
Kubernetesの開発とリリース中に遭遇した最も大きな課題は何ですか?これらの課題をどのように克服しましたか?
リリースのサイクルごとに、さまざまな課題が発生します。新たに発見されたCVE(Common Vulnerabilities and Exposures)のような土壇場の問題に取り組んだり、内部ツール内のバグを解決したり、以前のリリースの機能によって引き起こされた予期せぬリグレッションに対処したりすることもあります。私たちがしばしば直面するもう1つの障害は、私たちのチームは大規模ですが、私たちのほとんどがボランティアベースで貢献していることです。時には人手が足りないと感じることもありますが、私たちは常に組織化し、うまくやりくりしています。
-
新しい貢献者として、SIG Releaseに参加するための理想的な道はどのようなものでしょうか?誰もが自分のタスクに忙殺されているコミュニティで、効果的に貢献するために適切なタスクを見つけるにはどうすればいいのでしょうか?
オープンソースコミュニティへの関わり方は人それぞれです。SIG Releaseは、リリースを出荷できるように自分たちでツールを書くという、自分勝手なチームです。SIG K8s Infraのような他のSIGとのコラボレーションも多いのですが、私たちが使用するツールはすべて、コストを削減しつつ、私たちの大規模な技術的ニーズに合わせて作られたものでなければなりません。このため、「単に」リリースを作成するだけでなく、さまざまなタイプのプロジェクトを手伝ってくれるボランティアを常に探しています。
私たちの現在のプロジェクトでは、Goプログラミング、Kubernetes内部の理解、Linuxパッケージング、サプライチェーンセキュリティ、テクニカルライティング、一般的なオープンソースプロジェクトのメンテナンスなどのスキルが必要です。このスキルセットは、プロジェクトの成長とともに常に進化しています。
理想的な道筋として、私たちはこう提案します:
- どのように機能が管理されているか、リリースカレンダー、リリースチームの全体的な構造など、コードに慣れる。
- Slack(#sig-release)などのKubernetesコミュニティのコミュニケーションチャンネルに参加する。
- コミュニティ全員が参加できるSIG Releaseウィークリーミーティングに参加する。これらのミーティングに参加することは、あなたのスキルセットや興味に関連すると思われる進行中のプロジェクトや将来のプロジェクトについて学ぶ素晴らしい方法です。
経験豊富な貢献者は皆、かつてあなたのような立場にあったことを忘れないでください。遠慮せずに質問し、議論に参加し、貢献するための小さな一歩を踏み出しましょう。

-
リリースシャドウプログラムとは何ですか?また、他の様々なSIGに含まれるシャドウプログラムとの違いは何ですか?
リリースシャドウプログラムは、Kubernetesのリリースサイクルを通して、リリースチームの経験豊富なメンバーをシャドウイングする機会を提供します。これは、Kubernetesのリリースに必要な、サブチームにまたがるすべての困難な仕事を見るまたとないチャンスです。多くの人は、私たちの仕事は3ヶ月ごとにリリースを切ることだけだと思っていますが、それは氷山の一角にすぎません。
私たちのプログラムは通常、特定のKubernetesリリースサイクルに沿っており、それは約3ヶ月の予測可能なタイムラインを持っています。このプログラムではKubernetesの新機能を書くことはありませんが、リリースチームは新リリースと何千人ものコントリビューターとの最後のステップであるため、高い責任感が求められます。
-
一般的に、次のKubernetesリリースのリリースシャドウ/リリースリードとしてボランティアに参加する人に求める資格は何ですか?
どの役割もある程度の技術的能力を必要としますが、Goの実践的な経験やKubernetes APIに精通していることを必要とするものもあれば、技術的な内容を明確かつ簡潔に伝えるのが得意な人を必要とするものもあります。技術的な専門知識よりも、熱意とコミットメントを重視しています。もしあなたが正しい姿勢を持っていて、Kubernetesやリリース・エンジニアリングの仕事を楽しんでいることが伝われば、たとえそれがあなたが余暇を利用して立ち上げた個人的なプロジェクトであったとしても、チームは必ずあなたを指導します。セルフスターターであること、そして質問をすることを恐れないことは、私たちのチームであなたを大きく前進させます。
-
リリースシャドープログラムに何度も不合格になった人に何を勧めますか?
応募し続けることです。
リリースサイクルごとに応募者数が飛躍的に増えているため、選ばれるのが難しくなり、落胆することもありますが、不採用になったからといって、あなたに才能がないというわけではないことを知っておいてください。すべての応募者を受け入れることは現実的に不可能です、しかし、ここに私たちが提案する代替案があります。:
毎週開催されるKubernetes SIGのリリースミーティングに参加して、自己紹介をし、チームや私たちが取り組んでいるプロジェクトに慣れてください。
リリースチームはSIG Releaseに参加する方法の1つですが、私たちは常に手伝ってくれる人を探しています。繰り返しになりますが、一定の技術的な能力に加えて、私たちが最も求めている特性は、信頼できる人であり、それには時間が必要です。

-
リリースチームがKubernetes v1.28に特に期待している進行中の取り組みや今後の機能について教えてください。これらの進歩は、Kubernetesの長期的なビジョンとどのように整合しているのでしょうか?
Kubernetesのパッケージをコミュニティインフラ上でついに公開できることに興奮しています。数年前からやりたいと思っていたことですが、移行する前に整えなければならない技術的な意味合いが多いプロジェクトです。それが終われば、生産性を向上させ、ワークフロー全体をコントロールできるようになります。
最後に
さて、この対談はここで終わりですが、学習はこれで終わりではありません。このインタビューが、SIG Releaseが何をしているのか、そしてどのように手助けを始めたらいいのか、ある程度わかっていただけたと思います。重要なこととして、この記事はSIG Releaseの最初のサブプロジェクトであるリリース・チームを取り上げています。次回のSIG Releaseのスポットライトブログでは、Release Engineeringサブプロジェクトにスポットライトを当て、その活動内容や参加方法について紹介します。最後に、SIG Releaseの運営方法についてより深く理解するために、SIG Release憲章をご覧ください。
フォレンジックコンテナ分析
Authors: Adrian Reber (Red Hat)
前回投稿したKubernetesにおけるフォレンジックコンテナチェックポイント処理では、Kubernetesでのチェックポイントの作成や、それがどのようにセットアップされ、どのように使用されるのかを紹介しました。 機能の名前はフォレンジックコンテナチェックポイントですが、Kubernetesによって作成されたチェックポイントの実際の分析方法については、詳細を説明しませんでした。 この記事では、チェックポイントがどのように分析されるのかについての詳細を提供します。
チェックポイントの作成はまだKubernetesでalpha機能であり、この記事ではその機能が将来どのように動作するのかについてのプレビューを提供します。
準備
チェックポイント作成のサポートを有効にするためのKubernetesの設定方法や、基盤となるCRI実装方法についての詳細はKubernetesにおけるフォレンジックコンテナチェックポイント処理を参照してください。
一例として、この記事内でチェックポイントを作成し分析するコンテナイメージ(quay.io/adrianreber/counter:blog)を準備しました。
このコンテナはコンテナ内でファイルを作成することができ、後でチェックポイント内で探したい情報をメモリーに格納しておくこともできます。
コンテナを実行するためにはPodが必要であり、この例では下記のPodマニフェストを使用します。
apiVersion: v1
kind: Pod
metadata:
name: counters
spec:
containers:
- name: counter
image: quay.io/adrianreber/counter:blog
この結果、counterと呼ばれるコンテナがcountersと呼ばれるPod内で実行されます。
一度コンテナが実行されると、コンテナで下記アクションが行えます。
$ kubectl get pod counters --template '{{.status.podIP}}'
10.88.0.25
$ curl 10.88.0.25:8088/create?test-file
$ curl 10.88.0.25:8088/secret?RANDOM_1432_KEY
$ curl 10.88.0.25:8088
最初のアクセスはコンテナ内でtest-fileという内容でtest-fileと呼ばれるファイルを作成します。
次のアクセスで、コンテナのメモリー内のどこかにシークレット情報(RANDOM_1432_KEY)を記憶します。
最後のアクセスは内部のログファイルに1行追加するだけです。
チェックポイントを分析する前の最後のステップは、チェックポイントを作成することをKubernetesに指示することです。
前回の記事で説明したように、これにはkubelet限定のチェックポイントAPIエンドポイントへのアクセスを必要とします。
default名前空間内のcountersという名前のPod内のcounterという名前のコンテナに対して、kubelet APIエンドポイントが次の場所で到達可能です。
# Podが実行されているNode上で実行する
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
厳密には、kubeletの自己署名証明書を許容しkubelet チェックポイントAPIの使用を認可するために、下記のcurlコマンドのオプションが必要です。
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
チェックポイントの作成が終了すると、/var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tarでチェックポイントが利用可能になります。
この記事の後述のステップでは、チェックポイントアーカイブを分析する際にcheckpoint.tarという名前を使用します。
checkpointctlを使用したチェックポイントアーカイブの分析
チェックポイントが作成したコンテナに関するいくつかの初期情報を得るためには、このようにcheckpointctlを使用します。
$ checkpointctl show checkpoint.tar --print-stats
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| CONTAINER | IMAGE | ID | RUNTIME | CREATED | ENGINE | IP | CHKPT SIZE | ROOT FS DIFF SIZE |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| counter | quay.io/adrianreber/counter:blog | 059a219a22e5 | runc | 2023-03-02T06:06:49 | CRI-O | 10.88.0.23 | 8.6 MiB | 3.0 KiB |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
CRIU dump statistics
+---------------+-------------+--------------+---------------+---------------+---------------+
| FREEZING TIME | FROZEN TIME | MEMDUMP TIME | MEMWRITE TIME | PAGES SCANNED | PAGES WRITTEN |
+---------------+-------------+--------------+---------------+---------------+---------------+
| 100809 us | 119627 us | 11602 us | 7379 us | 7800 | 2198 |
+---------------+-------------+--------------+---------------+---------------+---------------+
これによって、チェックポイントアーカイブ内のチェックポイントについてのいくつかの情報が、すでに取得できています。
コンテナの名前やコンテナランタイムやコンテナエンジンについての情報を見ることができます。
チェックポイントのサイズ(CHKPT SIZE)もリスト化されます。
これは大部分がチェックポイントに含まれるメモリーページのサイズですが、コンテナ内の全ての変更されたファイルのサイズ(ROOT FS DIFF SIZE)についての情報もあります。
追加のパラメーター--print-statsはチェックポイントアーカイブ内の情報を復号化し、2番目のテーブル(CRIU dump statistics)で表示します。
この情報はチェックポイント作成中に収集され、CRIUがコンテナ内のプロセスをチェックポイントするために必要な時間と、チェックポイント作成中に分析され書き込まれたメモリーページ数の概要を示します。
より深く掘り下げる
checkpointctlの助けを借りて、チェックポイントアーカイブについてのハイレベルな情報を得ることができます。
チェックポイントアーカイブをさらに分析するには、それを展開する必要があります。
チェックポイントアーカイブはtarアーカイブであり、tar xf checkpoint.tarの助けを借りて展開可能です。
チェックポイントアーカイブを展開すると、下記のファイルやディレクトリが作成されます。
bind.mounts- このファイルにはバインドマウントについての情報が含まれており、復元中に全ての外部ファイルとディレクトリを正しい場所にマウントするために必要になります。checkpoint/- このディレクトリにはCRIUによって作成された実際のチェックポイントが含まれています。config.dumpとspec.dump- これらのファイルには、復元中に必要とされるコンテナについてのメタデータが含まれています。dump.log- このファイルにはチェックポイント作成中に作成されたCRIUのデバッグ出力が含まれています。stats-dump- このファイルには、checkpointctlが--print-statsでダンプ統計情報を表示するために使用するデータが含まれています。rootfs-diff.tar- このファイルには、コンテナのファイルシステム上で変更された全てのファイルが含まれています。
ファイルシステムの変更 - rootfs-diff.tar
コンテナのチェックポイントをさらに分析するための最初のステップは、コンテナ内で変更されたファイルを見ることです。
これはrootfs-diff.tarファイルを参照することで行えます。
$ tar xvf rootfs-diff.tar
home/counter/logfile
home/counter/test-file
これでコンテナ内で変更されたファイルを調べられます。
$ cat home/counter/logfile
10.88.0.1 - - [02/Mar/2023 06:07:29] "GET /create?test-file HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:40] "GET /secret?RANDOM_1432_KEY HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:43] "GET / HTTP/1.1" 200 -
$ cat home/counter/test-file
test-file
このコンテナのベースになっているコンテナイメージ(quay.io/adrianreber/counter:blog)と比較すると、コンテナが提供するサービスへの全てのアクセス情報を含んだlogfileや予想通り作成されたtest-fileファイルを確認することができます。
rootfs-diff.tarの助けを借りることで、作成または変更された全てのファイルを、コンテナのベースイメージと比較して検査することが可能です。
チェックポイント処理したプロセスを分析する - checkpoint/
ディレクトリcheckpoint/はコンテナ内でプロセスをチェックポイントしている間にCRIUによって作成されたデータを含んでいます。
ディレクトリcheckpoint/の内容は、CRIUの一部として配布されているCRITツールを使用して分析できるさまざまなイメージファイルで構成されています。
まず、コンテナの内部プロセスの概要を取得してみましょう。
$ crit show checkpoint/pstree.img | jq .entries[].pid
1
7
8
この出力はコンテナのPID名前空間の内部に3つのプロセス(PIDが1と7と8)があることを意味しています。
これはコンテナのPID名前空間の内部からの視界を表示しているだけです。 復元中に正確にそれらのPIDが再作成されます。 コンテナのPID名前空間の外部からPIDは復元後に変更されます。
次のステップは、それらの3つのプロセスについての追加情報を取得することです。
$ crit show checkpoint/core-1.img | jq .entries[0].tc.comm
"bash"
$ crit show checkpoint/core-7.img | jq .entries[0].tc.comm
"counter.py"
$ crit show checkpoint/core-8.img | jq .entries[0].tc.comm
"tee"
これは、コンテナ内の3つのプロセスがbashとcounter.py(Pythonインタプリター)とteeであることを意味しています。
プロセスの親子関係についての詳細は、checkpoint/pstree.imgに分析するデータがさらにあります。
ここまでで収集した情報をまだ実行中のコンテナと比較してみましょう。
$ crictl inspect --output go-template --template "{{(index .info.pid)}}" 059a219a22e56
722520
$ ps auxf | grep -A 2 722520
fedora 722520 \_ bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile
fedora 722541 \_ /usr/bin/python3 /home/counter/counter.py
fedora 722542 \_ /usr/bin/coreutils --coreutils-prog-shebang=tee /usr/bin/tee /home/counter/logfile
$ cat /proc/722520/comm
bash
$ cat /proc/722541/comm
counter.py
$ cat /proc/722542/comm
tee
この出力では、まずコンテナ内の最初のプロセスのPIDを取得しています。
そしてコンテナを実行しているシステム上で、そのPIDと子プロセスを探しています。
3つのプロセスが表示され、最初のものはコンテナPID名前空間の中でPID 1である"bash"です。
次に/proc/<PID>/commを見ると、チェックポイントイメージと正確に同じ値を見つけることができます。
覚えておく重要なことは、チェックポイントはコンテナのPID名前空間内の視界が含まれていることです。 なぜなら、これらの情報はプロセスを復元するために重要だからです。
critがコンテナについて教えてくれる最後の例は、UTS名前空間に関する情報です。
$ crit show checkpoint/utsns-12.img
{
"magic": "UTSNS",
"entries": [
{
"nodename": "counters",
"domainname": "(none)"
}
]
}
UTS名前空間内のホストネームがcountersであることを教えてくれます。
チェックポイント作成中に収集された各リソースCRIUについて、checkpoint/ディレクトリは対応するイメージファイルを含んでいます。
このイメージファイルはcritを使用することで分析可能です。
メモリーページを見る
CRITを使用して復号化できるCRIUからの情報に加えて、CRIUがディスクに書き込んだ生のメモリーページを含んでいるファイルもあります。
$ ls checkpoint/pages-*
checkpoint/pages-1.img checkpoint/pages-2.img checkpoint/pages-3.img
最初にコンテナを使用した際に、メモリー内のどこかにランダムキー(RANDOM_1432_KEY)を保存しました。
見つけることができるかどうか見てみましょう。
$ grep -ao RANDOM_1432_KEY checkpoint/pages-*
checkpoint/pages-2.img:RANDOM_1432_KEY
そして実際に、私のデータがあります。 この方法で、コンテナ内のプロセスの全てのメモリーページの内容を簡単に見ることができます。 しかし、チェックポイントアーカイブにアクセスできるなら誰でも、コンテナのプロセスのメモリー内に保存された全ての情報にアクセスできることを覚えておくことも重要です。
さらなる分析のためにgdbを使用する
チェックポイントイメージを見るための他の方法はgdbです。
CRIUリポジトリは、チェックポイントをコアダンプファイルに変換するcoredumpスクリプトを含んでいます。
$ /home/criu/coredump/coredump-python3
$ ls -al core*
core.1 core.7 core.8
coredump-python3スクリプトを実行すると、チェックポイントイメージがコンテナ内の各プロセスに対し1つのコアダンプファイルに変換されます。
gdbを使用してプロセスの詳細を見ることもできます。
$ echo info registers | gdb --core checkpoint/core.1 -q
[New LWP 1]
Core was generated by `bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile'.
#0 0x00007fefba110198 in ?? ()
(gdb)
rax 0x3d 61
rbx 0x8 8
rcx 0x7fefba11019a 140667595587994
rdx 0x0 0
rsi 0x7fffed9c1110 140737179816208
rdi 0xffffffff 4294967295
rbp 0x1 0x1
rsp 0x7fffed9c10e8 0x7fffed9c10e8
r8 0x1 1
r9 0x0 0
r10 0x0 0
r11 0x246 582
r12 0x0 0
r13 0x7fffed9c1170 140737179816304
r14 0x0 0
r15 0x0 0
rip 0x7fefba110198 0x7fefba110198
eflags 0x246 [ PF ZF IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
この例では、チェックポイント中の全てのレジストリの値を見ることができ、コンテナのPID 1のプロセスの完全なコマンドライン(bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile)を見ることもできます。
まとめ
コンテナチェックポイントを作成することで、コンテナを停止することやチェックポイントが作成されたことを知ることなく、実行中のコンテナのチェックポイントを作成することが可能です。
Kubernetesにおいてコンテナのチェックポイントを作成した結果がチェックポイントアーカイブです。
checkpointctlやtar、crit、gdbのような異なるツールを使用して、チェックポイントを分析できます。
grepのようなシンプルなツールでさえ、チェックポイントアーカイブ内の情報を見つけることが可能です。
この記事で示したチェックポイントの分析方法のさまざまな例は出発点にすぎません。 この記事ではチェックポイントの分析を始める方法を紹介しましたが、要件によってはかなり詳細に特定の物事を見ることも可能です。
参加するためにはどうすればよいですか?
SIG Nodeにはいくつかの方法でアクセスできます。
- Slack: #sig-node
- Slack: #sig-security
- メーリングリスト
Kubernetes 1.26: PodDisruptionBudgetによって保護された不健全なPodに対する退避ポリシー
著者: Filip Křepinský (Red Hat), Morten Torkildsen (Google), Ravi Gudimetla (Apple)
アプリケーションの中断がその可用性に影響を与えないようにすることは、簡単な作業ではありません。 先月リリースされたKubernetes v1.26では、PodDisruptionBudget (PDB) に 不健全なPodの退避ポリシー を指定して、ノード管理操作中に可用性を維持できるようになりました。 この記事では、アプリケーション所有者が中断をより柔軟に管理できるようにするために、PDBにどのような変更が導入されたのかを詳しく説明します。
これはどのような問題を解決しますか?
APIによって開始されるPodの退避では、PodDisruptionBudget(PDB)が考慮されます。
これは、退避によるPodへの自発的な中断の要求は保護されたアプリケーションを中断してはならず、
PDBの.status.currentHealthyが.status.desiredHealthyを下回ってはいけないことを意味します。
Unhealthyな実行中のPodはPDBステータスにはカウントされませんが、
これらの退避はアプリケーションが中断されない場合にのみ可能です。
これにより、中断されたアプリケーションやまだ開始されていないアプリケーションが、退避によって追加のダウンタイムが発生することなく、できるだけ早く可用性を達成できるようになります。
残念ながら、これは手動の介入なしでノードをドレインしたいクラスター管理者にとって問題を引き起こします。
(バグまたは構成ミスにより)PodがCrashLoopBackOff状態になっているアプリケーション、または単に準備ができていないPodがあるアプリケーションが誤動作している場合、このタスクはさらに困難になります。
アプリケーションのすべてのPodが正常でない場合、PDBの違反により退避リクエストは失敗します。その場合、ノードのドレインは進行できません。
一方で、次の目的で従来の動作に依存するユーザーもいます。
- 基盤となるリソースまたはストレージを保護しているPodの削除によって引き起こされるデータ損失を防止する
- アプリケーションに対して可能な限り最高の可用性を実現する
Kubernetes 1.26では、PodDisruptionBudget APIに新しい実験的フィールド.spec.unhealthyPodEvictionPolicyが導入されました。
このフィールドを有効にすると、これらの要件の両方をサポートできるようになります。
どのように機能しますか?
APIによって開始される退避は、Podの安全な終了をトリガーするプロセスです。
このプロセスは、APIを直接呼び出すか、kubectl drainコマンドを使用するか、クラスター内の他のアクターを使用して開始できます。
このプロセス中に、十分な数のPodが常にクラスター内で実行されていることを確認するために、すべてのPodの削除が適切なPDBと照合されます。
次のポリシーにより、PDBの作成者は、プロセスが不健全なPodを処理する方法をより詳細に制御できるようになります。
IfHealthyBudgetとAlwaysAllowの2つのポリシーから選択できます。
前者のIfHealthyBudgetは、従来の動作に従って、デフォルトで得られる最高の可用性を実現します。
不健全なPodは、アプリケーションが利用可能な最小数の.status.desiredHealthyだけPodがある場合にのみ中断できます。
PDBのspec.unhealthyPodEvictionPolicyフィールドをAlwaysAllowに設定することにより、アプリケーションにとってベストエフォートの可用性を選択することになります。
このポリシーを使用すると、不健全なPodをいつでも削除できます。これにより、クラスターの保守とアップグレードが容易になります。
多くの場合、AlwaysAllowがより良い選択であると考えられますが、一部の重要なワークロードでは、
不健全なPodであってもノードドレインやAPIによって開始される他の形式の退避から保護する方が望ましい場合もあります。
どのように利用できますか?
これはアルファ機能であるため、kube-apiserverに対してコマンドライン引数--feature-gates=PDBUnhealthyPodEvictionPolicy=trueを指定して
PDBUnhealthyPodEvictionPolicyフィーチャーゲートを有効にする必要があります。
ここに例を示します。クラスターでフィーチャーゲートを有効にし、プレーンなWebサーバーを実行するDeploymentをすでに定義していると仮定します。
そのDeploymentのPodにapp: nginxというラベルを付けました。
回避可能な中断を制限したいと考えており、このアプリにはベストエフォートの可用性で十分であることがわかっています。
WebサーバーのPodが不健全な場合でも、退避を許可することにしました。
不健全なPodを排除するためのAlwaysAllowポリシーを使用して、このアプリケーションを保護するPDBを作成します。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
selector:
matchLabels:
app: nginx
maxUnavailable: 1
unhealthyPodEvictionPolicy: AlwaysAllow
もっと学ぶには?
- KEPを読んでください: Unhealthy Pod Eviction Policy for PDBs
- PodDisruptionBudgetについてのドキュメントを読んでください: Unhealthy Pod Eviction Policy
- PodDisruptionBudget、draining of NodesおよびevictionsについてKubernetesドキュメントを確認してください
どうすれば参加できますか?
フィードバックがある場合は、Slackの#sig-apps チャンネル(必要な場合は https://slack.k8s.io/ にアクセスして招待を受けてください)、またはSIG Appsメーリングリストにご連絡ください。kubernetes-sig-apps@googlegroups.com
Kubernetesにおけるフォレンジックコンテナチェックポイント処理
Authors: Adrian Reber (Red Hat)
フォレンジックコンテナチェックポイント処理はCheckpoint/Restore In Userspace (CRIU)に基づいており、コンテナがチェックポイントされていることを認識することなく、実行中のコンテナのステートフルコピーを作成することができます。 コンテナのコピーは、元のコンテナに気づかれることなく、サンドボックス環境で複数回の分析やリストアが可能です。 フォレンジックコンテナチェックポイント処理はKubernetes v1.25でalpha機能として導入されました。
どのように機能しますか?
CRIUを使用してコンテナのチェックポイントやリストアを行うことが可能です。 CRIUはruncやcrun、CRI-O、containerdと統合されており、Kubernetesで実装されているフォレンジックコンテナチェックポイント処理は、既存のCRIU統合を使用します。
なぜ重要なのか?
CRIUと対応する統合機能を使用することで、後でフォレンジック分析を行うために、ディスク上で実行中のコンテナに関する全ての情報と状態を取得することが可能です。 フォレンジック分析は、疑わしいコンテナを停止したり影響を与えることなく検査するために重要となる場合があります。 コンテナが本当に攻撃を受けている場合、攻撃者はコンテナを検査する処理を検知するかもしれません。 チェックポイントを取得しサンドボックス環境でコンテナを分析することは、元のコンテナや、おそらく攻撃者にも検査を認識されることなく、コンテナを検査することができる可能性があります。
フォレンジックコンテナチェックポイント処理のユースケースに加えて、内部状態を失うことなく、あるノードから他のノードにコンテナを移行することも可能です。 特に初期化時間の長いステートフルコンテナの場合、チェックポイントからリストアすることは再起動後の時間が節約されるか、起動時間がより早くなる可能性があります。
コンテナチェックポイント処理を利用するには?
機能はフィーチャーゲートで制限されているため、新しい機能を使用する前にContainerCheckpointを有効にしてください。
ランタイムがコンテナチェックポイント処理をサポートしている必要もあります。
- containerd: サポートは現在検討中です。詳細はcontainerdプルリクエスト#6965を見てください。
- CRI-O: v1.25はフォレンジックコンテナチェックポイント処理をサポートしています。
CRI-Oでの使用例
CRI-Oとの組み合わせでフォレンジックコンテナチェックポイント処理を使用するためには、ランタイムをコマンドラインオプション--enable-criu-support=trueで起動する必要があります。
Kubernetesでは、ContainerCheckpointフィーチャーゲートを有効にしたクラスターを実行する必要があります。
チェックポイント処理の機能はCRIUによって提供されているため、CRIUをインストールすることも必要となります。
通常、runcやcrunはCRIUに依存しているため、自動的にインストールされます。
執筆時点ではチェックポイント機能はCRI-OやKubernetesにおいてalpha機能としてみなされており、セキュリティ影響がまだ検討中であることに言及することも重要です。
コンテナとPodが実行されると、チェックポイントを作成することが可能になります。
チェックポイント処理はkubeletレベルでのみ公開されています。
コンテナをチェックポイントするためには、コンテナが実行されているノード上でcurlを実行し、チェックポイントをトリガーします。
curl -X POST "https://localhost:10250/checkpoint/namespace/podId/container"
default名前空間内のcountersと呼ばれるPod内のcounterと呼ばれるコンテナに対し、kubelet APIエンドポイントが次の場所で到達可能です。
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
厳密には、kubeletの自己署名証明書を許容し、kubeletチェックポイントAPIの使用を認可するために、下記のcurlコマンドのオプションが必要です。
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
このkubelet APIが実行されると、CRI-Oからチェックポイントの作成をリクエストします。
CRI-Oは低レベルランタイム(例えばrunc)からチェックポイントをリクエストします。
そのリクエストを確認すると、runcは実際のチェックポイントを行うためにcriuツールを呼び出します。
チェックポイント処理が終了すると、チェックポイントは/var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tarで利用可能になります。
その後、そのtarアーカイブを使用してコンテナを別の場所にリストアできます。
Kubernetesの外部でチェックポイントしたコンテナをリストアする(CRI-Oを使用)
チェックポイントtarアーカイブを使用すると、CRI-Oのサンドボックスインスタンス内のKubernetesの外部にコンテナをリストア可能です。 リストア中のより良いユーザエクスペリエンスのために、main CRI-O GitHubブランチからCRI-Oのlatestバージョンを使用することを推奨します。 CRI-O v1.25を使用している場合、コンテナを開始する前にKubernetesが作成する特定のディレクトリを手動で作成する必要があります。
Kubernetesの外部にコンテナをリストアするための最初のステップは、crictlを使用してPodサンドボックスを作成することです。
crictl runp pod-config.json
次に、さきほどチェックポイントしたコンテナを新しく作成したPodサンドボックスにリストアします。
crictl create <POD_ID> container-config.json pod-config.json
container-config.jsonのレジストリでコンテナイメージを指定する代わりに、前に作成したチェックポイントアーカイブへのパスを指定する必要があります。
{
"metadata": {
"name": "counter"
},
"image":{
"image": "/var/lib/kubelet/checkpoints/<checkpoint-archive>.tar"
}
}
次に、そのコンテナを開始するためにcrictl start <CONTAINER_ID>を実行すると、さきほどチェックポイントしたコンテナのコピーが実行されているはずです。
Kubernetes内でチェックポイントしたコンテナをリストアする
先ほどチェックポイントしたコンテナをKubernetes内で直接リストアするためには、レジストリにプッシュできるイメージにチェックポイントアーカイブを変換する必要があります。
ローカルのチェックポイントアーカイブを変換するための方法として、buildahを使用した下記のステップが考えられます。
newcontainer=$(buildah from scratch)
buildah add $newcontainer /var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tar /
buildah config --annotation=io.kubernetes.cri-o.annotations.checkpoint.name=<container-name> $newcontainer
buildah commit $newcontainer checkpoint-image:latest
buildah rm $newcontainer
出来上がったイメージは標準化されておらず、CRI-Oとの組み合わせでのみ動作します。
このイメージはalphaにも満たないフォーマットであると考えてください。
このようなチェックポイントイメージのフォーマットを標準化するための議論が進行中です。
これはまだ標準化されたイメージフォーマットではなく、CRI-Oを--enable-criu-support=trueで起動した場合のみ動作することを忘れないでください。
CRIUサポートでCRI-Oを起動することのセキュリティ影響はまだ明確ではなく、そのため、イメージフォーマットだけでなく機能も気を付けて使用するべきです。
さて、そのイメージをコンテナイメージレジストリにプッシュする必要があります。 例えば以下のような感じです。
buildah push localhost/checkpoint-image:latest container-image-registry.example/user/checkpoint-image:latest
このチェックポイントイメージ(container-image-registry.example/user/checkpoint-image:latest)をリストアするために、イメージはPodの仕様(Specification)に記載する必要があります。
以下はマニフェストの例です。
apiVersion: v1
kind: Pod
metadata:
namePrefix: example-
spec:
containers:
- name: <container-name>
image: container-image-registry.example/user/checkpoint-image:latest
nodeName: <destination-node>
Kubernetesは新しいPodをノード上にスケジュールします。
そのノード上のKubeletは、registry/user/checkpoint-image:latestとして指定されたイメージをもとに、コンテナを作成し開始するようにコンテナランタイム(この例ではCRI-O)に指示をします。
CRI-Oはregistry/user/checkpoint-image:latestがコンテナイメージでなく、チェックポイントデータへの参照であることを検知します。
その時、コンテナを作成し開始する通常のステップの代わりに、CRI-Oはチェックポイントデータをフェッチし、指定されたチェックポイントからコンテナをリストアします。
Pod内のアプリケーションはチェックポイントを取得しなかったかのように実行し続けます。 コンテナ内では、アプリケーションはチェックポイントからリストアされず通常起動したコンテナのような見た目や動作をします。
これらのステップで、あるノードで動作しているPodを、別のノードで動作している新しい同等のPodに置き換えることができ、そのPod内のコンテナの状態を失うことはないです。
どのように参加すればよいですか?
SIG Nodeにはいくつかの手段でアクセスすることができます。
さらなる読み物
コンテナチェックポイントの分析方法に関する詳細は後続のブログForensic container analysisを参照してください。
更新: dockershimの削除に関するFAQ
この記事は2020年の後半に投稿されたオリジナルの記事Dockershim Deprecation FAQの更新版です。 この記事にはv1.24のリリースに関する更新を含みます。
この文書では、Kubernetesからの dockershim の削除に関するよくある質問について説明します。 この削除はKubernetes v1.20リリースの一部としてはじめて発表されたものです。 Kubernetes v1.24のリリースにおいてdockershimは実際にKubernetesから削除されました。
これが何を意味するかについては、ブログ記事Don't Panic: Kubernetes and Dockerをご覧ください。
dockershim削除の影響範囲を確認するをお読みいただくことで、 dockershimの削除があなたやあなたの組織に与える影響をご判断いただけます。
Kubernetes 1.24リリースに至るまでの間、Kubernetesコントリビューターはこの移行を円滑に行えるようにするために尽力してきました。
- 私たちのコミットメントと次のステップを詳述したブログ記事。
- 他のコンテナランタイムへの移行に大きな障害があるかどうかのチェック。
- dockershimからの移行ガイドの追加。
- dockershimの削除とCRI互換ランタイムの使用に関する記事一覧の作成。 このリストには、上に示した文書の一部が含まれており、また、厳選された外部の情報(ベンダーによるガイドを含む)もカバーしています。
dockershimはなぜKubernetesから削除されたのですか?
Kubernetesの初期のバージョンは、特定のコンテナランタイム上でのみ動作しました。 Docker Engineです。その後、Kubernetesは他のコンテナランタイムと連携するためのサポートを追加しました。 オーケストレーター(Kubernetesなど)と多くの異なるコンテナランタイムの間の相互運用を可能にするため、 CRI標準が作成されました。 Docker Engineはそのインターフェイス(CRI)を実装していないため、Kubernetesプロジェクトは移行を支援する特別なコードを作成し、 その dockershim コードをKubernetes自身の一部としました。
dockershimコードは常に一時的な解決策であることを意図されていました(このためshimと名付けられています)。 コミュニティでの議論や計画については、dockershimの削除によるKubernetes改良の提案にてお読みいただけます。
実際、dockershimのメンテナンスはKubernetesメンテナーにとって大きな負担になっていました。
さらに、dockershimとほとんど互換性のなかった機能、たとえばcgroups v2やユーザーネームスペースなどが、 これらの新しいCRIランタイムに実装されています。Kubernetesからdockershimを削除することで、これらの分野でのさらなる開発が可能になります。
Dockerとコンテナは同じものですか?
DockerはLinuxのコンテナパターンを普及させ、その基盤技術の発展に寄与してきましたが、 Linuxのコンテナ技術そのものはかなり以前から存在しています。 また、コンテナエコシステムはDockerを超えてより広範に発展してきました。 OCIやCRIのような標準は、Dockerの機能の一部を置き換えたり、既存の機能を強化したりすることで、 私達のエコシステムの多くのツールの成長と繁栄を助けてきました。
既存のコンテナイメージは引き続き使えるのですか?
はい、docker buildから生成されるイメージは、全てのCRI実装で動作します。
既存のイメージも全く同じように動作します。
プライベートイメージについてはどうでしょうか?
はい、すべてのCRIランタイムはKubernetesで使われているものと同一のpull secretsをサポートしており、 PodSpecまたはService Accountを通して利用できます。
Kubernetes 1.23でDocker Engineを引き続き使用できますか?
はい、1.20で変更されたのは、Docker Engineランタイムを使用している場合に警告ログがkubelet起動時に出るようになったことだけです。 この警告は、1.23までのすべてのバージョンで表示されます。 dockershimの削除はKubernetes 1.24で行われました。
Kubernetes v1.24以降を実行している場合は、Docker Engineを引き続きコンテナランタイムとして利用できますか?をご覧ください。 (CRIがサポートされているKubernetesリリースを使用している場合、dockershimから切り替えることができることを忘れないでください。 リリースv1.24からはKubernetesにdockershimが含まれなくなったため、必ず切り替えなければなりません)。
どのCRIの実装を使うべきでしょうか?
これは難しい質問で、様々な要素に依存します。 もしDocker Engineがうまく動いているのであれば、containerdに移行するのは比較的簡単で、 性能もオーバーヘッドも確実に改善されるでしょう。 しかし、他の選択のほうがあなたの環境により適合する場合もありますので、 CNCF landscapeにあるすべての選択肢を検討されることをおすすめします。
Docker Engineを引き続きコンテナランタイムとして利用できますか?
第一に、ご自身のPCで開発やテスト用途でDockerを使用している場合、何も変わることはありません。 Kubernetesでどのコンテナランタイムを使っていても、Dockerをローカルで使い続けることができます。 コンテナではこのような相互運用性を実現できます。
MirantisとDockerは、Kubernetesから内蔵のdockershimが削除された後も、
Docker Engineの代替アダプターを維持することにコミットしています。
代替アダプターの名前はcri-dockerdです。
cri-dockerdをインストールして、kubeletをDocker Engineに接続するために使用することができます。
詳細については、Migrate Docker Engine nodes from dockershim to cri-dockerdを読んでください。
今現在でプロダクション環境に他のランタイムを使用している例はあるのでしょうか?
Kubernetesプロジェクトが生み出したすべての成果物(Kubernetesバイナリ)は、リリースごとに検証されています。
また、kindプロジェクトは以前からcontainerdを使っており、プロジェクトのユースケースにおいて安定性が向上してきています。 kindとcontainerdは、Kubernetesコードベースの変更を検証するために毎日何回も利用されています。 他の関連プロジェクトも同様のパターンを追っており、他のコンテナランタイムの安定性と使いやすさが示されています。 例として、OpenShift 4.xは2019年6月以降、CRI-Oランタイムをプロダクション環境で使っています。
他の事例や参考資料はについては、 containerdとCRI-O(Cloud Native Computing Foundation (CNCF)の2つのコンテナランタイム)の採用例をご覧ください。
OCIという単語をよく見るのですが、これは何ですか?
OCIはOpen Container Initiativeの略で、コンテナツールとテクノロジー間の数多くのインターフェースの標準化を行った団体です。 彼らはコンテナイメージをパッケージするための標準仕様(OCI image-spec)と、 コンテナを実行するための標準仕様(OCI runtime-spec)をメンテナンスしています。 また、runcという形でruntime-specの実装もメンテナンスしており、 これはcontainerdとCRI-Oの両方でデフォルトの下位ランタイムとなっています。 CRIはこれらの低レベル仕様に基づいて、コンテナを管理するためのエンドツーエンドの標準を提供します。
CRI実装を変更する際に注意すべきことは何ですか?
DockerとほとんどのCRI(containerdを含む)において、下位で使用されるコンテナ化コードは同じものですが、 いくつかの細かい違いが存在します。移行する際に考慮すべき一般的な事項は次のとおりです。
- ログ設定
- ランタイムリソースの制限
- ノード構成スクリプトでdockerコマンドやコントロールソケット経由でDocker Engineを使用しているもの
kubectlのプラグインでdockerCLIまたはDocker Engineコントロールソケットが必要なもの- KubernetesプロジェクトのツールでDocker Engineへの直接アクセスが必要なもの(例:廃止された
kube-imagepullerツール) registry-mirrorsやinsecureレジストリなどの機能の設定- その他の支援スクリプトやデーモンでDocker Engineが利用可能であることを想定していてKubernetes外で実行されるもの(モニタリング・セキュリティエージェントなど)
- GPUまたは特別なハードウェア、そしてランタイムおよびKubernetesとそれらハードウェアの統合方法
あなたがKubernetesのリソース要求/制限やファイルベースのログ収集DaemonSetを使用しているのであれば、それらは問題なく動作し続けますが、
dockerdの設定をカスタマイズしていた場合は、それを新しいコンテナランタイムに適合させる必要があるでしょう。
他に注意することとしては、システムメンテナンスを実行するようなものや、コンテナ内でイメージをビルドするようなものが動作しなくなります。
前者の場合は、crictlツールをdrop-inの置き換えとして使用できます(docker cliからcrictlへのマッピングを参照)。
後者の場合は、img、buildah、kaniko、buildkit-cli-for-kubectlのようなDockerを必要としない新しいコンテナビルドの選択肢を使用できます。
containerdを使っているのであれば、ドキュメントを参照して、移行するのにどのような構成が利用可能かを確認するところから始めるといいでしょう。
containerdとCRI-OをKubernetesで使用する方法に関しては、コンテナランタイムに関するKubernetesのドキュメントを参照してください。
さらに質問がある場合どうすればいいでしょうか?
ベンダーサポートのKubernetesディストリビューションを使用している場合、彼らの製品に対するアップグレード計画について尋ねることができます。 エンドユーザーの質問に関しては、エンドユーザーコミュニティフォーラムに投稿してください。
dockershimの削除に関する決定については、専用のGitHub issueで議論することができます。
変更点に関するより詳細な技術的な議論は、待ってください、DockerはKubernetesで非推奨になったのですか?という素晴らしいブログ記事も参照してください。
dockershimを使っているかどうかを検出できるツールはありますか?
はい!Detector for Docker Socket (DDS)というkubectlプラグインをインストールすることであなたのクラスターを確認していただけます。
DDSは、アクティブなKubernetesワークロードがDocker Engineソケット(docker.sock)をボリュームとしてマウントしているかを検出できます。
さらなる詳細と使用パターンについては、DDSプロジェクトのREADMEを参照してください。
ハグしていただけますか?
はい、私達は引き続きいつでもハグに応じています。🤗🤗🤗
Don't Panic: Kubernetes and Docker
著者: Jorge Castro, Duffie Cooley, Kat Cosgrove, Justin Garrison, Noah Kantrowitz, Bob Killen, Rey Lejano, Dan “POP” Papandrea, Jeffrey Sica, Davanum “Dims” Srinivas
Kubernetesはv1.20より新しいバージョンで、コンテナランタイムとしてDockerをサポートしません。
パニックを起こす必要はありません。これはそれほど抜本的なものではないのです。
概要: ランタイムとしてのDockerは、Kubernetesのために開発されたContainer Runtime Interface(CRI)を利用しているランタイムを選んだ結果としてサポートされなくなります。しかし、Dockerによって生成されたイメージはこれからも、今までもそうだったように、みなさんのクラスターで使用可能です。
もし、あなたがKubernetesのエンドユーザーであるならば、多くの変化はないでしょう。これはDockerの死を意味するものではありませんし、開発ツールとして今後Dockerを使用するべきでない、使用することは出来ないと言っているのでもありません。Dockerはコンテナを作成するのに便利なツールですし、docker buildコマンドで作成されたイメージはKubernetesクラスター上でこれからも動作可能なのです。
もし、GKE、EKS、AKSといったマネージドKubernetesサービス(それらはデフォルトでcontainerdを使用しています)を使っているのなら、ワーカーノードがサポート対象のランタイムを使用しているか、Dockerのサポートが将来のK8sバージョンで切れる前に確認しておく必要があるでしょう。 もし、ノードをカスタマイズしているのなら、環境やRuntimeの仕様に合わせて更新する必要があるでしょう。サービスプロバイダーと確認し、アップグレードのための適切なテストと計画を立ててください。
もし、ご自身でClusterを管理しているのなら、やはり問題が発生する前に必要な対応を行う必要があります。v1.20の時点で、Dockerの使用についての警告メッセージが表示されるようになります。将来のKubernetesリリース(現在の計画では2021年下旬のv1.22)でDockerのRuntimeとしての使用がサポートされなくなれば、containerdやCRI-Oといった他のサポート対象のRuntimeに切り替える必要があります。切り替える際、そのRuntimeが現在使用しているDocker Daemonの設定をサポートすることを確認してください。(Loggingなど)
では、なぜ混乱が生じ、誰もが恐怖に駆られているのか。
ここで議論になっているのは2つの異なる場面についてであり、それが混乱の原因になっています。Kubernetesクラスターの内部では、Container runtimeと呼ばれるものがあり、それはImageをPullし起動する役目を持っています。Dockerはその選択肢として人気があります(他にはcontainerdやCRI-Oが挙げられます)が、しかしDockerはそれ自体がKubernetesの一部として設計されているわけではありません。これが問題の原因となっています。
お分かりかと思いますが、ここで”Docker”と呼んでいるものは、ある1つのものではなく、その技術的な体系の全体であり、その一部には"containerd"と呼ばれるものもあり、これはそれ自体がハイレベルなContainer runtimeとなっています。Dockerは素晴らしいもので、便利です。なぜなら、多くのUXの改善がされており、それは人間が開発を行うための操作を簡単にしているのです。しかし、それらはKubernetesに必要なものではありません。Kubernetesは人間ではないからです。 このhuman-friendlyな抽象化レイヤーが作られたために、結果としてはKubernetesクラスターはDockershimと呼ばれるほかのツールを使い、本当に必要な機能つまりcontainerdを利用してきました。これは素晴らしいとは言えません。なぜなら、我々がメンテする必要のあるものが増えますし、それは問題が発生する要因ともなります。今回の変更で実際に行われることというのは、Dockershimを最も早い場合でv1.23のリリースでkubeletから除外することです。その結果として、Dockerのサポートがなくなるということなのです。 ここで、containerdがDockerに含まれているなら、なぜDockershimが必要なのかと疑問に思われる方もいるでしょう。
DockerはCRI(Container Runtime Interface)に準拠していません。もしそうであればshimは必要ないのですが、現実はそうでありません。 しかし、これは世界の終わりでありません、心配しないでください。みなさんはContainer runtimeをDockerから他のサポート対象であるContainer runtimeに切り替えるだけでよいのです。
1つ注意すべきことは、クラスターで行われる処理のなかでDocker socket(/var/run/docker.sock)に依存する部分がある場合、他のRuntimeへ切り替えるとこの部分が働かなくなるでしょう。このパターンはしばしばDocker in Dockerと呼ばれます。このような場合の対応方法はたくさんあります。kaniko、img、buildahなどです。
では開発者にとって、この変更は何を意味するのか。これからもDockerfileを使ってよいのか。これからもDockerでビルドを行ってよいのか。
この変更は、Dockerを直接操作している多くのみなさんとは別の場面に影響を与えるでしょう。 みなさんが開発を行う際に使用しているDockerと、Kubernetesクラスターの内部で使われているDocker runtimeは関係ありません。これがわかりにくいことは理解しています。開発者にとって、Dockerはこれからも便利なものであり、このアナウンスがあった前と変わらないでしょう。DockerでビルドされたImageは、決してDockerでだけ動作するというわけではありません。それはOCI(Open Container Initiative) Imageと呼ばれるものです。あらゆるOCI準拠のImageは、それを何のツールでビルドしたかによらず、Kubernetesから見れば同じものなのです。containerdもCRI-Oも、そのようなImageをPullし、起動することが出来ます。 これがコンテナの仕様について、共通の仕様を策定している理由なのです。
さて、この変更は決定しています。いくつかの問題は発生するかもしてませんが、決して壊滅的なものではなく、ほとんどの場合は良い変化となるでしょう。Kubernetesをどのように使用しているかによりますが、この変更が特に何の影響も及ぼさない人もいるでしょうし、影響がとても少ない場合もあります。長期的に見れば、物事を簡単にするのに役立つものです。 もし、この問題がまだわかりにくいとしても、心配しないでください。Kubernetesでは多くのものが変化しており、その全てに完璧に精通している人など存在しません。 経験の多寡や難易度にかかわらず、どんなことでも質問してください。我々の目標は、全ての人が将来の変化について、可能な限りの知識と理解を得られることです。 このブログが多くの質問の答えとなり、不安を和らげることができればと願っています。
別の情報をお探しであれば、dockershimの削除に関するFAQを参照してください。