这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
调度、抢占和驱逐
在 Kubernetes 中,调度(scheduling)指的是确保 Pod 匹配到合适的节点, 以便 kubelet 能够运行它们。抢占(Preemption)指的是终止低优先级的 Pod 以便高优先级的 Pod 可以调度运行的过程。驱逐(Eviction)是在资源匮乏的节点上,主动让一个或多个 Pod 失效的过程。
在 Kubernetes 中,调度(scheduling)指的是确保 Pod
匹配到合适的节点 ,
以便 kubelet 能够运行它们。
抢占(Preemption)指的是终止低优先级 的
Pod 以便高优先级的 Pod 可以调度运行的过程。
驱逐(Eviction)是在资源匮乏的节点上,主动让一个或多个 Pod 失效的过程。
调度
Pod 干扰
Pod 干扰 是指节点上的
Pod 被自愿或非自愿终止的过程。
自愿干扰是由应用程序所有者或集群管理员有意启动的。非自愿干扰是无意的,
可能由不可避免的问题触发,如节点耗尽资源或意外删除。
1 - Kubernetes 调度器
在 Kubernetes 中,调度 是指将 Pod
放置到合适的节点 上,以便对应节点上的
Kubelet 能够运行这些 Pod。
调度概览
调度器通过 Kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的 Pod。
调度器会将所发现的每一个未调度的 Pod 调度到一个合适的节点上来运行。
调度器会依据下文的调度原则来做出调度选择。
如果你想要理解 Pod 为什么会被调度到特定的节点上,
或者你想要尝试实现一个自定义的调度器,这篇文章将帮助你了解调度。
kube-scheduler
kube-scheduler
是 Kubernetes 集群的默认调度器,并且是集群
控制面 的一部分。
如果你真得希望或者有这方面的需求,kube-scheduler
在设计上允许你自己编写一个调度组件并替换原有的 kube-scheduler。
Kube-scheduler 选择一个最佳节点来运行新创建的或尚未调度(unscheduled)的 Pod。
由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的节点。
或者,API 允许你在创建 Pod 时为它指定一个节点,但这并不常见,并且仅在特殊情况下才会这样做。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为可调度节点 。
如果没有任何一个节点能满足 Pod 的资源请求,
那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分,
选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给
kube-apiserver,这个过程叫做绑定 。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、
亲和以及反亲和要求、数据局部性、负载间的干扰等等。
kube-scheduler 中的节点选择
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤:
过滤
打分
过滤阶段会将所有满足 Pod 调度需求的节点选出来。
例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。
在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下,
这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。
根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的节点上。
如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
支持以下两种方式配置调度器的过滤和打分行为:
调度策略
允许你配置过滤所用的 断言(Predicates) 和打分所用的 优先级(Priorities) 。调度配置 允许你配置实现不同调度阶段的插件,
包括:QueueSort、Filter、Score、Bind、Reserve、Permit 等等。
你也可以配置 kube-scheduler 运行不同的配置文件。
接下来
2 - 将 Pod 指派给节点
你可以约束一个 Pod
以便 限制 其只能在特定的节点 上运行,
或优先在特定的节点上运行。有几种方法可以实现这点,推荐的方法都是用
标签选择算符 来进行选择。
通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上,
而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制
Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上,
或者将来自两个不同的服务且有大量通信的 Pod 被放置在同一个可用区。
你可以使用下列方法中的任何一种来选择 Kubernetes 对特定 Pod 的调度:
节点标签
与很多其他 Kubernetes 对象类似,节点也有标签 。
你可以手动地添加标签 。
Kubernetes 也会为集群中所有节点添加一些标准的标签 。
说明:
这些标签的取值是取决于云提供商的,并且是无法在可靠性上给出承诺的。
例如,kubernetes.io/hostname 的取值在某些环境中可能与节点名称相同,
而在其他环境中会取不同的值。
节点隔离/限制
通过为节点添加标签,你可以准备让 Pod 调度到特定节点或节点组上。
你可以使用这个功能来确保特定的 Pod 只能运行在具有一定隔离性、安全性或监管属性的节点上。
如果使用标签来实现节点隔离,建议选择节点上的
kubelet
无法修改的标签键。
这可以防止受感染的节点在自身上设置这些标签,进而影响调度器将工作负载调度到受感染的节点。
NodeRestriction 准入插件node-restriction.kubernetes.io/ 前缀设置或修改标签。
要使用该标签前缀进行节点隔离:
确保你在使用节点鉴权 机制并且已经启用了
NodeRestriction 准入插件 。
将带有 node-restriction.kubernetes.io/ 前缀的标签添加到 Node 对象,
然后在节点选择算符 中使用这些标签。
例如,example.com.node-restriction.kubernetes.io/fips=true 或
example.com.node-restriction.kubernetes.io/pci-dss=true。
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到
Pod 的规约中设置你希望目标节点所具有的节点标签 。
Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
进一步的信息可参见将 Pod 指派给节点 。
亲和性与反亲和性
nodeSelector 提供了一种最简单的方法来将 Pod 约束到具有特定标签的节点上。
亲和性和反亲和性扩展了你可以定义的约束类型。使用亲和性与反亲和性的一些好处有:
亲和性、反亲和性语言的表达能力更强。nodeSelector 只能选择拥有所有指定标签的节点。
亲和性、反亲和性为你提供对选择逻辑的更强控制能力。
你可以标明某规则是“软需求”或者“偏好”,这样调度器在无法找到匹配节点时仍然调度该 Pod。
你可以使用节点上(或其他拓扑域中)运行的其他 Pod 的标签来实施调度约束,
而不是只能使用节点本身的标签。这个能力让你能够定义规则允许哪些 Pod 可以被放置在一起。
亲和性功能由两种类型的亲和性组成:
节点亲和性 功能类似于 nodeSelector 字段,但它的表达能力更强,并且允许你指定软规则。Pod 间亲和性/反亲和性允许你根据其他 Pod 的标签来约束 Pod。
节点亲和性
节点亲和性概念上类似于 nodeSelector,
它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。
节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution:
调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector,
但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution:
调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
说明:
在上述类型中,IgnoredDuringExecution 意味着如果节点标签在 Kubernetes
调度 Pod 后发生了变更,Pod 仍将继续运行。
你可以使用 Pod 规约中的 .spec.affinity.nodeAffinity 字段来设置节点亲和性。
例如,考虑下面的 Pod 规约:
apiVersion : v1
kind : Pod
metadata :
name : with-node-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : topology.kubernetes.io/zone
operator : In
values :
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : another-node-label-key
operator : In
values :
- another-node-label-value
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0
在这一示例中,所应用的规则如下:
节点必须 包含一个键名为 topology.kubernetes.io/zone 的标签,
并且该标签的取值必须 为 antarctica-east1 或 antarctica-west1。
节点最好 具有一个键名为 another-node-label-key 且取值为
another-node-label-value 的标签。
你可以使用 operator 字段来为 Kubernetes 设置在解释规则时要使用的逻辑操作符。
你可以使用 In、NotIn、Exists、DoesNotExist、Gt 和 Lt 之一作为操作符。
阅读操作符 了解有关这些操作的更多信息。
NotIn 和 DoesNotExist 可用来实现节点反亲和性行为。
你也可以使用节点污点
将 Pod 从特定节点上驱逐。
说明:
如果你同时指定了 nodeSelector 和 nodeAffinity,两者 必须都要满足,
才能将 Pod 调度到候选节点上。
如果你在与 nodeAffinity 类型关联的 nodeSelectorTerms 中指定多个条件,
只要其中一个 nodeSelectorTerms 满足(各个条件按逻辑或操作组合)的话,Pod 就可以被调度到节点上。
如果你在与 nodeSelectorTerms 中的条件相关联的单个 matchExpressions 字段中指定多个表达式,
则只有当所有表达式都满足(各表达式按逻辑与操作组合)时,Pod 才能被调度到节点上。
参阅使用节点亲和性来为 Pod 指派节点 ,
以了解进一步的信息。
节点亲和性权重
你可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置
weight 字段,其取值范围是 1 到 100。
当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则,
并将对应表达式的 weight 值加和。
最终的加和值会添加到该节点的其他优先级函数的评分之上。
在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
例如,考虑下面的 Pod 规约:
apiVersion : v1
kind : Pod
metadata :
name : with-affinity-anti-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/os
operator : In
values :
- linux
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : label-1
operator : In
values :
- key-1
- weight : 50
preference :
matchExpressions :
- key : label-2
operator : In
values :
- key-2
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0
如果存在两个候选节点,都满足 preferredDuringSchedulingIgnoredDuringExecution 规则,
其中一个节点具有标签 label-1:key-1,另一个节点具有标签 label-2:key-2,
调度器会考察各个节点的 weight 取值,并将该权重值添加到节点的其他得分值之上,
说明:
如果你希望 Kubernetes 能够成功地调度此例中的 Pod,你必须拥有打了
kubernetes.io/os=linux 标签的节点。
逐个调度方案中设置节点亲和性
特性状态: Kubernetes v1.20 [beta]
在配置多个调度方案 时,
你可以将某个方案与节点亲和性关联起来,如果某个调度方案仅适用于某组特殊的节点时,
这样做是很有用的。
要实现这点,可以在调度器配置 中为
NodeAffinity 插件args 字段添加 addedAffinity。例如:
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
- schedulerName : foo-scheduler
pluginConfig :
- name : NodeAffinity
args :
addedAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : scheduler-profile
operator : In
values :
- foo
这里的 addedAffinity 除遵从 Pod 规约中设置的节点亲和性之外,
还适用于将 .spec.schedulerName 设置为 foo-scheduler。
换言之,为了匹配 Pod,节点需要满足 addedAffinity 和 Pod 的 .spec.NodeAffinity。
由于 addedAffinity 对最终用户不可见,其行为可能对用户而言是出乎意料的。
应该使用与调度方案名称有明确关联的节点标签。
说明:
DaemonSet 控制器为 DaemonSet 创建 Pod ,
但该控制器不理会调度方案。
DaemonSet 控制器创建 Pod 时,默认的 Kubernetes 调度器负责放置 Pod,
并遵从 DaemonSet 控制器中设置的 nodeAffinity 规则。
Pod 间亲和性与反亲和性
Pod 间亲和性与反亲和性使你可以基于已经在节点上运行的 Pod 的标签来约束
Pod 可以调度到的节点,而不是基于节点上的标签。
Pod 间亲和性与反亲和性的规则格式为“如果 X 上已经运行了一个或多个满足规则 Y 的 Pod,
则这个 Pod 应该(或者在反亲和性的情况下不应该)运行在 X 上”。
这里的 X 可以是节点、机架、云提供商可用区或地理区域或类似的拓扑域,
Y 则是 Kubernetes 尝试满足的规则。
你通过标签选择算符
的形式来表达规则(Y),并可根据需要指定选关联的名字空间列表。
Pod 在 Kubernetes 中是名字空间作用域的对象,因此 Pod 的标签也隐式地具有名字空间属性。
针对 Pod 标签的所有标签选择算符都要指定名字空间,Kubernetes
会在指定的名字空间内寻找标签。
你会通过 topologyKey 来表达拓扑域(X)的概念,其取值是系统用来标示域的节点标签键。
相关示例可参见常用标签、注解和污点 。
说明:
Pod 间亲和性和反亲和性都需要相当的计算量,因此会在大规模集群中显著降低调度速度。
我们不建议在包含数百个节点的集群中使用这类设置。
说明:
Pod 反亲和性需要节点上存在一致性的标签。换言之,
集群中每个节点都必须拥有与 topologyKey 匹配的标签。
如果某些或者所有节点上不存在所指定的 topologyKey 标签,调度行为可能与预期的不同。
Pod 间亲和性与反亲和性的类型
与节点亲和性 类似,Pod 的亲和性与反亲和性也有两种类型:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
例如,你可以使用 requiredDuringSchedulingIgnoredDuringExecution 亲和性来告诉调度器,
将两个服务的 Pod 放到同一个云提供商可用区内,因为它们彼此之间通信非常频繁。
类似地,你可以使用 preferredDuringSchedulingIgnoredDuringExecution
反亲和性来将同一服务的多个 Pod 分布到多个云提供商可用区中。
要使用 Pod 间亲和性,可以使用 Pod 规约中的 .affinity.podAffinity 字段。
对于 Pod 间反亲和性,可以使用 Pod 规约中的 .affinity.podAntiAffinity 字段。
调度一组具有 Pod 间亲和性的 Pod
如果当前正被调度的 Pod 在具有自我亲和性的 Pod 序列中排在第一个,
那么只要它满足其他所有的亲和性规则,它就可以被成功调度。
这是通过以下方式确定的:确保集群中没有其他 Pod 与此 Pod 的名字空间和标签选择算符匹配;
该 Pod 满足其自身定义的条件,并且选定的节点满足所指定的所有拓扑要求。
这确保即使所有的 Pod 都配置了 Pod 间亲和性,也不会出现调度死锁的情况。
Pod 亲和性示例
考虑下面的 Pod 规约:
apiVersion : v1
kind : Pod
metadata :
name : with-pod-affinity
spec :
affinity :
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S1
topologyKey : topology.kubernetes.io/zone
podAntiAffinity :
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 100
podAffinityTerm :
labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S2
topologyKey : topology.kubernetes.io/zone
containers :
- name : with-pod-affinity
image : registry.k8s.io/pause:2.0
本示例定义了一条 Pod 亲和性规则和一条 Pod 反亲和性规则。Pod 亲和性规则配置为
requiredDuringSchedulingIgnoredDuringExecution,而 Pod 反亲和性配置为
preferredDuringSchedulingIgnoredDuringExecution。
亲和性规则规定,只有节点属于特定的
区域
且该区域中的其他 Pod 已打上 security=S1 标签时,调度器才可以将示例 Pod 调度到此节点上。
例如,如果我们有一个具有指定区域(称之为 "Zone V")的集群,此区域由带有 topology.kubernetes.io/zone=V
标签的节点组成,那么只要 Zone V 内已经至少有一个 Pod 打了 security=S1 标签,
调度器就可以将此 Pod 调度到 Zone V 内的任何节点。相反,如果 Zone V 中没有带有 security=S1 标签的 Pod,
则调度器不会将示例 Pod 调度给该区域中的任何节点。
反亲和性规则规定,如果节点属于特定的
区域
且该区域中的其他 Pod 已打上 security=S2 标签,则调度器应尝试避免将 Pod 调度到此节点上。
例如,如果我们有一个具有指定区域(我们称之为 "Zone R")的集群,此区域由带有 topology.kubernetes.io/zone=R
标签的节点组成,只要 Zone R 内已经至少有一个 Pod 打了 security=S2 标签,
调度器应避免将 Pod 分配给 Zone R 内的任何节点。相反,如果 Zone R 中没有带有 security=S2 标签的 Pod,
则反亲和性规则不会影响将 Pod 调度到 Zone R。
查阅设计文档
以进一步熟悉 Pod 亲和性与反亲和性的示例。
你可以针对 Pod 间亲和性与反亲和性为其 operator 字段使用 In、NotIn、Exists、
DoesNotExist 等值。
阅读操作符 了解有关这些操作的更多信息。
原则上,topologyKey 可以是任何合法的标签键。出于性能和安全原因,topologyKey
有一些限制:
对于 Pod 亲和性而言,在 requiredDuringSchedulingIgnoredDuringExecution
和 preferredDuringSchedulingIgnoredDuringExecution 中,topologyKey
不允许为空。
对于 requiredDuringSchedulingIgnoredDuringExecution 要求的 Pod 反亲和性,
准入控制器 LimitPodHardAntiAffinityTopology 要求 topologyKey 只能是
kubernetes.io/hostname。如果你希望使用其他定制拓扑逻辑,
你可以更改准入控制器或者禁用之。
除了 labelSelector 和 topologyKey,你也可以指定 labelSelector
要匹配的名字空间列表,方法是在 labelSelector 和 topologyKey
所在层同一层次上设置 namespaces。
如果 namespaces 被忽略或者为空,则默认为 Pod 亲和性/反亲和性的定义所在的名字空间。
名字空间选择算符
特性状态: Kubernetes v1.24 [stable]
用户也可以使用 namespaceSelector 选择匹配的名字空间,namespaceSelector
是对名字空间集合进行标签查询的机制。
亲和性条件会应用到 namespaceSelector 所选择的名字空间和 namespaces 字段中所列举的名字空间之上。
注意,空的 namespaceSelector({})会匹配所有名字空间,而 null 或者空的
namespaces 列表以及 null 值 namespaceSelector 意味着“当前 Pod 的名字空间”。
更实际的用例
Pod 间亲和性与反亲和性在与更高级别的集合(例如 ReplicaSet、StatefulSet、
Deployment 等)一起使用时,它们可能更加有用。
这些规则使得你可以配置一组工作负载,使其位于所定义的同一拓扑中;
例如优先将两个相关的 Pod 置于相同的节点上。
以一个三节点的集群为例。你使用该集群运行一个带有内存缓存(例如 Redis)的 Web 应用程序。
在此例中,还假设 Web 应用程序和内存缓存之间的延迟应尽可能低。
你可以使用 Pod 间的亲和性和反亲和性来尽可能地将该 Web 服务器与缓存并置。
在下面的 Redis 缓存 Deployment 示例中,副本上设置了标签 app=store。
podAntiAffinity 规则告诉调度器避免将多个带有 app=store 标签的副本部署到同一节点上。
因此,每个独立节点上会创建一个缓存实例。
apiVersion : apps/v1
kind : Deployment
metadata :
name : redis-cache
spec :
selector :
matchLabels :
app : store
replicas : 3
template :
metadata :
labels :
app : store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : redis-server
image : redis:3.2-alpine
下例的 Deployment 为 Web 服务器创建带有标签 app=web-store 的副本。
Pod 亲和性规则告诉调度器将每个副本放到存在标签为 app=store 的 Pod 的节点上。
Pod 反亲和性规则告诉调度器决不要在单个节点上放置多个 app=web-store 服务器。
apiVersion : apps/v1
kind : Deployment
metadata :
name : web-server
spec :
selector :
matchLabels :
app : web-store
replicas : 3
template :
metadata :
labels :
app : web-store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- web-store
topologyKey : "kubernetes.io/hostname"
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : web-app
image : nginx:1.16-alpine
创建前面两个 Deployment 会产生如下的集群布局,每个 Web 服务器与一个缓存实例并置,
并分别运行在三个独立的节点上。
node-1
node-2
node-3
webserver-1 webserver-2 webserver-3
cache-1 cache-2 cache-3
总体效果是每个缓存实例都非常可能被在同一个节点上运行的某个客户端访问。
这种方法旨在最大限度地减少偏差(负载不平衡)和延迟。
你可能还有使用 Pod 反亲和性的一些其他原因。
参阅 ZooKeeper 教程
了解一个 StatefulSet 的示例,该 StatefulSet 配置了反亲和性以实现高可用,
所使用的是与此例相同的技术。
nodeName
nodeName 是比亲和性或者 nodeSelector 更为直接的形式。nodeName 是 Pod
规约中的一个字段。如果 nodeName 字段不为空,调度器会忽略该 Pod,
而指定节点上的 kubelet 会尝试将 Pod 放到该节点上。
使用 nodeName 规则的优先级会高于使用 nodeSelector 或亲和性与非亲和性的规则。
使用 nodeName 来选择节点的方式有一些局限性:
如果所指代的节点不存在,则 Pod 无法运行,而且在某些情况下可能会被自动删除。
如果所指代的节点无法提供用来运行 Pod 所需的资源,Pod 会失败,
而其失败原因中会给出是否因为内存或 CPU 不足而造成无法运行。
在云环境中的节点名称并不总是可预测的,也不总是稳定的。
说明:
nodeName 旨在供自定义调度器或需要绕过任何已配置调度器的高级场景使用。
如果已分配的 Node 负载过重,绕过调度器可能会导致 Pod 失败。
你可以使用节点亲和性 或 nodeselector 字段
下面是一个使用 nodeName 字段的 Pod 规约示例:
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx
nodeName : kube-01
上面的 Pod 只能运行在节点 kube-01 之上。
Pod 拓扑分布约束
你可以使用 拓扑分布约束(Topology Spread Constraints) 来控制
Pod 在集群内故障域之间的分布,
故障域的示例有区域(Region)、可用区(Zone)、节点和其他用户自定义的拓扑域。
这样做有助于提升性能、实现高可用或提升资源利用率。
阅读 Pod 拓扑分布约束
以进一步了解这些约束的工作方式。
操作符
下面是你可以在上述 nodeAffinity 和 podAffinity 的 operator
字段中可以使用的所有逻辑运算符。
操作符
行为
In标签值存在于提供的字符串集中
NotIn标签值不包含在提供的字符串集中
Exists对象上存在具有此键的标签
DoesNotExist对象上不存在具有此键的标签
以下操作符只能与 nodeAffinity 一起使用。
操作符
行为
Gt提供的值将被解析为整数,并且该整数小于通过解析此选择算符命名的标签的值所得到的整数
Lt提供的值将被解析为整数,并且该整数大于通过解析此选择算符命名的标签的值所得到的整数
说明:
Gt 和 Lt 操作符不能与非整数值一起使用。
如果给定的值未解析为整数,则该 Pod 将无法被调度。
另外,Gt 和 Lt 不适用于 podAffinity。
接下来
3 - Pod 开销
特性状态: Kubernetes v1.24 [stable]
在节点上运行 Pod 时,Pod 本身占用大量系统资源。这些是运行 Pod 内容器所需资源之外的资源。
在 Kubernetes 中,POD 开销 是一种方法,用于计算 Pod 基础设施在容器请求和限制之上消耗的资源。
在 Kubernetes 中,Pod 的开销是根据与 Pod 的 RuntimeClass
相关联的开销在准入 时设置的。
在调度 Pod 时,除了考虑容器资源请求的总和外,还要考虑 Pod 开销。
类似地,kubelet 将在确定 Pod cgroups 的大小和执行 Pod 驱逐排序时也会考虑 Pod 开销。
配置 Pod 开销
你需要确保使用一个定义了 overhead 字段的 RuntimeClass。
使用示例
要使用 Pod 开销,你需要一个定义了 overhead 字段的 RuntimeClass。
作为例子,下面的 RuntimeClass 定义中包含一个虚拟化所用的容器运行时,
RuntimeClass 如下,其中每个 Pod 大约使用 120MiB 用来运行虚拟机和寄宿操作系统:
apiVersion : node.k8s.io/v1
kind : RuntimeClass
metadata :
name : kata-fc
handler : kata-fc
overhead :
podFixed :
memory : "120Mi"
cpu : "250m"
通过指定 kata-fc RuntimeClass 处理程序创建的工作负载会将内存和 CPU
开销计入资源配额计算、节点调度以及 Pod cgroup 尺寸确定。
假设我们运行下面给出的工作负载示例 test-pod:
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
runtimeClassName : kata-fc
containers :
- name : busybox-ctr
image : busybox:1.28
stdin : true
tty : true
resources :
limits :
cpu : 500m
memory : 100Mi
- name : nginx-ctr
image : nginx
resources :
limits :
cpu : 1500m
memory : 100Mi
在准入阶段 RuntimeClass 准入控制器
更新工作负载的 PodSpec 以包含
RuntimeClass 中定义的 overhead。如果 PodSpec 中已定义该字段,该 Pod 将会被拒绝。
在这个例子中,由于只指定了 RuntimeClass 名称,所以准入控制器更新了 Pod,使之包含 overhead。
在 RuntimeClass 准入控制器进行修改后,你可以查看更新后的 Pod 开销值:
kubectl get pod test-pod -o jsonpath = '{.spec.overhead}'
输出:
map[cpu:250m memory:120Mi]
如果定义了 ResourceQuota ,
则容器请求的总量以及 overhead 字段都将计算在内。
当 kube-scheduler 决定在哪一个节点调度运行新的 Pod 时,调度器会兼顾该 Pod 的
overhead 以及该 Pod 的容器请求总量。在这个示例中,调度器将资源请求和开销相加,
然后寻找具备 2.25 CPU 和 320 MiB 内存可用的节点。
一旦 Pod 被调度到了某个节点, 该节点上的 kubelet 将为该 Pod 新建一个
cgroup 。 底层容器运行时将在这个
Pod 中创建容器。
如果该资源对每一个容器都定义了一个限制(定义了限制值的 Guaranteed QoS 或者
Burstable QoS),kubelet 会为与该资源(CPU 的 cpu.cfs_quota_us 以及内存的
memory.limit_in_bytes)
相关的 Pod cgroup 设定一个上限。该上限基于 PodSpec 中定义的容器限制总量与 overhead 之和。
对于 CPU,如果 Pod 的 QoS 是 Guaranteed 或者 Burstable,kubelet 会基于容器请求总量与
PodSpec 中定义的 overhead 之和设置 cpu.shares。
请看这个例子,验证工作负载的容器请求:
kubectl get pod test-pod -o jsonpath = '{.spec.containers[*].resources.limits}'
容器请求总计 2000m CPU 和 200MiB 内存:
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
对照从节点观察到的情况来检查一下:
kubectl describe node | grep test-pod -B2
该输出显示请求了 2250m CPU 以及 320MiB 内存。请求包含了 Pod 开销在内:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
验证 Pod cgroup 限制
在工作负载所运行的节点上检查 Pod 的内存 cgroups。在接下来的例子中,
将在该节点上使用具备 CRI 兼容的容器运行时命令行工具
crictl
# 在该 Pod 被调度到的节点上执行如下命令:
POD_ID = " $( sudo crictl pods --name test-pod -q) "
可以依此判断该 Pod 的 cgroup 路径:
# 在该 Pod 被调度到的节点上执行如下命令:
sudo crictl inspectp -o= json $POD_ID | grep cgroupsPath
执行结果的 cgroup 路径中包含了该 Pod 的 pause 容器。Pod 级别的 cgroup 在即上一层目录。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
在这个例子中,该 Pod 的 cgroup 路径是 kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2。
验证内存的 Pod 级别 cgroup 设置:
# 在该 Pod 被调度到的节点上执行这个命令。
# 另外,修改 cgroup 的名称以匹配为该 Pod 分配的 cgroup。
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
和预期的一样,这一数值为 320 MiB。
335544320
可观察性
在 kube-state-metrics 中可以通过
kube_pod_overhead_* 指标来协助确定何时使用 Pod 开销,
以及协助观察以一个既定开销运行的工作负载的稳定性。
该特性在 kube-state-metrics 的 1.9 发行版本中不可用,不过预计将在后续版本中发布。
在此之前,用户需要从源代码构建 kube-state-metrics。
接下来
4 - Pod 调度就绪态
特性状态: Kubernetes v1.27 [beta]
Pod 一旦创建就被认为准备好进行调度。
Kubernetes 调度程序尽职尽责地寻找节点来放置所有待处理的 Pod。
然而,在实际环境中,会有一些 Pod 可能会长时间处于"缺少必要资源"状态。
这些 Pod 实际上以一种不必要的方式扰乱了调度器(以及 Cluster AutoScaler 这类下游的集成方)。
通过指定或删除 Pod 的 .spec.schedulingGates,可以控制 Pod 何时准备好被纳入考量进行调度。
配置 Pod schedulingGates
schedulingGates 字段包含一个字符串列表,每个字符串文字都被视为 Pod 在被认为可调度之前应该满足的标准。
该字段只能在创建 Pod 时初始化(由客户端创建,或在准入期间更改)。
创建后,每个 schedulingGate 可以按任意顺序删除,但不允许添加新的调度门控。
图:Pod SchedulingGates
用法示例
要将 Pod 标记为未准备好进行调度,你可以在创建 Pod 时附带一个或多个调度门控,如下所示:
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
schedulingGates :
- name : foo
- name : bar
containers :
- name : pause
image : registry.k8s.io/pause:3.6
Pod 创建后,你可以使用以下方法检查其状态:
输出显示它处于 SchedulingGated 状态:
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
你还可以通过运行以下命令检查其 schedulingGates 字段:
kubectl get pod test-pod -o jsonpath = '{.spec.schedulingGates}'
输出是:
[{"name":"example.com/foo"},{"name":"example.com/bar"}]
要通知调度程序此 Pod 已准备好进行调度,你可以通过重新应用修改后的清单来完全删除其 schedulingGates:
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
containers :
- name : pause
image : registry.k8s.io/pause:3.6
你可以通过运行以下命令检查 schedulingGates 是否已被清空:
kubectl get pod test-pod -o jsonpath = '{.spec.schedulingGates}'
预计输出为空,你可以通过运行下面的命令来检查它的最新状态:
kubectl get pod test-pod -o wide
鉴于 test-pod 不请求任何 CPU/内存资源,预计此 Pod 的状态会从之前的
SchedulingGated 转变为 Running:
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
可观测性
指标 scheduler_pending_pods 带有一个新标签 "gated",
以区分 Pod 是否已尝试调度但被宣称不可调度,或明确标记为未准备好调度。
你可以使用 scheduler_pending_pods{queue="gated"} 来检查指标结果。
可变 Pod 调度指令
特性状态: Kubernetes v1.27 [beta]
当 Pod 具有调度门控时,你可以在某些约束条件下改变 Pod 的调度指令。
在高层次上,你只能收紧 Pod 的调度指令。换句话说,更新后的指令将导致
Pod 只能被调度到它之前匹配的节点子集上。
更具体地说,更新 Pod 的调度指令的规则如下:
对于 .spec.nodeSelector,只允许增加。如果原来未设置,则允许设置此字段。
对于 spec.affinity.nodeAffinity,如果当前值为 nil,则允许设置为任意值。
如果 NodeSelectorTerms 之前为空,则允许设置该字段。
如果之前不为空,则仅允许增加 NodeSelectorRequirements 到 matchExpressions
或 fieldExpressions,且不允许更改当前的 matchExpressions 和 fieldExpressions。
这是因为 .requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms
中的条目被执行逻辑或运算,而 nodeSelectorTerms[].matchExpressions 和
nodeSelectorTerms[].fieldExpressions 中的表达式被执行逻辑与运算。
对于 .preferredDuringSchedulingIgnoredDuringExecution,所有更新都被允许。
这是因为首选条目不具有权威性,因此策略控制器不会验证这些条目。
接下来
5 - Pod 拓扑分布约束
你可以使用 拓扑分布约束(Topology Spread Constraints) 来控制
Pod 在集群内故障域之间的分布,
例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域。
这样做有助于实现高可用并提升资源利用率。
你可以将集群级约束 设为默认值,或为个别工作负载配置拓扑分布约束。
动机
假设你有一个最多包含二十个节点的集群,你想要运行一个自动扩缩的
工作负载 ,请问要使用多少个副本?
答案可能是最少 2 个 Pod,最多 15 个 Pod。
当只有 2 个 Pod 时,你倾向于这 2 个 Pod 不要同时在同一个节点上运行:
你所遭遇的风险是如果放在同一个节点上且单节点出现故障,可能会让你的工作负载下线。
除了这个基本的用法之外,还有一些高级的使用案例,能够让你的工作负载受益于高可用性并提高集群利用率。
随着你的工作负载扩容,运行的 Pod 变多,将需要考虑另一个重要问题。
假设你有 3 个节点,每个节点运行 5 个 Pod。这些节点有足够的容量能够运行许多副本;
但与这个工作负载互动的客户端分散在三个不同的数据中心(或基础设施可用区)。
现在你可能不太关注单节点故障问题,但你会注意到延迟高于自己的预期,
在不同的可用区之间发送网络流量会产生一些网络成本。
你决定在正常运营时倾向于将类似数量的副本调度
到每个基础设施可用区,且你想要该集群在遇到问题时能够自愈。
Pod 拓扑分布约束使你能够以声明的方式进行配置。
topologySpreadConstraints 字段 Pod API 包括一个 spec.topologySpreadConstraints 字段。这个字段的用法如下所示:
---
apiVersion : v1
kind : Pod
metadata :
name : example-pod
spec :
# 配置一个拓扑分布约束
topologySpreadConstraints :
- maxSkew : <integer>
minDomains : <integer> # 可选;自从 v1.25 开始成为 Beta
topologyKey : <string>
whenUnsatisfiable : <string>
labelSelector : <object>
matchLabelKeys : <list> # 可选;自从 v1.27 开始成为 Beta
nodeAffinityPolicy : [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
nodeTaintsPolicy : [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
### 其他 Pod 字段置于此处
你可以运行 kubectl explain Pod.spec.topologySpreadConstraints 或参阅 Pod API
参考的调度 一节,
了解有关此字段的更多信息。
分布约束定义
你可以定义一个或多个 topologySpreadConstraints 条目以指导 kube-scheduler
如何将每个新来的 Pod 与跨集群的现有 Pod 相关联。这些字段包括:
topologyKey 是节点标签 的键。如果节点使用此键标记并且具有相同的标签值,
则将这些节点视为处于同一拓扑域中。我们将拓扑域中(即键值对)的每个实例称为一个域。
调度器将尝试在每个拓扑域中放置数量均衡的 Pod。
另外,我们将符合条件的域定义为其节点满足 nodeAffinityPolicy 和 nodeTaintsPolicy 要求的域。
whenUnsatisfiable 指示如果 Pod 不满足分布约束时如何处理:
DoNotSchedule(默认)告诉调度器不要调度。ScheduleAnyway 告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对节点进行排序。
labelSelector 用于查找匹配的 Pod。匹配此标签的 Pod 将被统计,以确定相应拓扑域中 Pod 的数量。
有关详细信息,请参考标签选择算符 。
matchLabelKeys 是一个 Pod 标签键的列表,用于选择需要计算分布方式的 Pod 集合。
这些键用于从 Pod 标签中查找值,这些键值标签与 labelSelector 进行逻辑与运算,以选择一组已有的 Pod,
通过这些 Pod 计算新来 Pod 的分布方式。matchLabelKeys 和 labelSelector 中禁止存在相同的键。
未设置 labelSelector 时无法设置 matchLabelKeys。Pod 标签中不存在的键将被忽略。
null 或空列表意味着仅与 labelSelector 匹配。
借助 matchLabelKeys,你无需在变更 Pod 修订版本时更新 pod.spec。
控制器或 Operator 只需要将不同修订版的标签键设为不同的值。
调度器将根据 matchLabelKeys 自动确定取值。例如,如果你正在配置一个 Deployment,
则你可以使用由 Deployment 控制器自动添加的、以
pod-template-hash
为键的标签来区分同一个 Deployment 的不同修订版。
topologySpreadConstraints :
- maxSkew : 1
topologyKey : kubernetes.io/hostname
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
app : foo
matchLabelKeys :
- pod-template-hash
说明:
matchLabelKeys 字段是 1.27 中默认启用的一个 Beta 级别字段。
你可以通过禁用 MatchLabelKeysInPodTopologySpread
特性门控 来禁用此字段。
当 Pod 定义了不止一个 topologySpreadConstraint,这些约束之间是逻辑与的关系。
kube-scheduler 会为新的 Pod 寻找一个能够满足所有约束的节点。
节点标签
拓扑分布约束依赖于节点标签来标识每个节点 所在的拓扑域。
例如,某节点可能具有标签:
region : us-east-1
zone : us-east-1a
说明:
为了简便,此示例未使用众所周知 的标签键
topology.kubernetes.io/zone 和 topology.kubernetes.io/region。
但是,建议使用那些已注册的标签键,而不是此处使用的私有(不合格)标签键 region 和 zone。
你无法对不同上下文之间的私有标签键的含义做出可靠的假设。
假设你有一个 4 节点的集群且带有以下标签:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
那么,从逻辑上看集群如下:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
一致性
你应该为一个组中的所有 Pod 设置相同的 Pod 拓扑分布约束。
通常,如果你正使用一个工作负载控制器,例如 Deployment,则 Pod 模板会帮你解决这个问题。
如果你混合不同的分布约束,则 Kubernetes 会遵循该字段的 API 定义;
但是,该行为可能更令人困惑,并且故障排除也没那么简单。
你需要一种机制来确保拓扑域(例如云提供商区域)中的所有节点具有一致的标签。
为了避免你需要手动为节点打标签,大多数集群会自动填充知名的标签,
例如 kubernetes.io/hostname。检查你的集群是否支持此功能。
拓扑分布约束示例
示例:一个拓扑分布约束
假设你拥有一个 4 节点集群,其中标记为 foo: bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
如果你希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其清单:
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
containers :
- name : pause
image : registry.k8s.io/pause:3.1
从此清单看,topologyKey: zone 意味着均匀分布将只应用于存在标签键值对为 zone: <any value> 的节点
(没有 zone 标签的节点将被跳过)。如果调度器找不到一种方式来满足此约束,
则 whenUnsatisfiable: DoNotSchedule 字段告诉该调度器将新来的 Pod 保持在 pending 状态。
如果该调度器将这个新来的 Pod 放到可用区 A,则 Pod 的分布将成为 [3, 1]。
这意味着实际偏差是 2(计算公式为 3 - 1),这违反了 maxSkew: 1 的约定。
为了满足这个示例的约束和上下文,新来的 Pod 只能放到可用区 B 中的一个节点上:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
或者
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
你可以调整 Pod 规约以满足各种要求:
将 maxSkew 更改为更大的值,例如 2,这样新来的 Pod 也可以放在可用区 A 中。
将 topologyKey 更改为 node,以便将 Pod 均匀分布在节点上而不是可用区中。
在上面的例子中,如果 maxSkew 保持为 1,则新来的 Pod 只能放到 node4 节点上。
将 whenUnsatisfiable: DoNotSchedule 更改为 whenUnsatisfiable: ScheduleAnyway,
以确保新来的 Pod 始终可以被调度(假设满足其他的调度 API)。但是,最好将其放置在匹配 Pod 数量较少的拓扑域中。
请注意,这一优先判定会与其他内部调度优先级(如资源使用率等)排序准则一起进行标准化。
示例:多个拓扑分布约束
下面的例子建立在前面例子的基础上。假设你拥有一个 4 节点集群,
其中 3 个标记为 foo: bar 的 Pod 分别位于 node1、node2 和 node3 上:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
可以组合使用 2 个拓扑分布约束来控制 Pod 在节点和可用区两个维度上的分布:
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
- maxSkew : 1
topologyKey : node
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
containers :
- name : pause
image : registry.k8s.io/pause:3.1
在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在可用区 B 中;
而在第二个约束中,新来的 Pod 只能调度到节点 node4 上。
该调度器仅考虑满足所有已定义约束的选项,因此唯一可行的选择是放置在节点 node4 上。
示例:有冲突的拓扑分布约束
多个约束可能导致冲突。假设有一个跨 2 个可用区的 3 节点集群:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
如果你将 two-constraints.yaml这个 集群,你将看到 Pod mypod 保持在 Pending 状态。
出现这种情况的原因为:为了满足第一个约束,Pod mypod 只能放置在可用区 B 中;
而在第二个约束中,Pod mypod 只能调度到节点 node2 上。
两个约束的交集将返回一个空集,且调度器无法放置该 Pod。
为了应对这种情形,你可以提高 maxSkew 的值或修改其中一个约束才能使用 whenUnsatisfiable: ScheduleAnyway。
根据实际情形,例如若你在故障排查时发现某个漏洞修复工作毫无进展,你还可能决定手动删除一个现有的 Pod。
与节点亲和性和节点选择算符的相互作用
如果 Pod 定义了 spec.nodeSelector 或 spec.affinity.nodeAffinity,
调度器将在偏差计算中跳过不匹配的节点。
示例:带节点亲和性的拓扑分布约束
假设你有一个跨可用区 A 到 C 的 5 节点集群:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
而且你知道可用区 C 必须被排除在外。在这种情况下,可以按如下方式编写清单,
以便将 Pod mypod 放置在可用区 B 上,而不是可用区 C 上。
同样,Kubernetes 也会一样处理 spec.nodeSelector。
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : zone
operator : NotIn
values :
- zoneC
containers :
- name : pause
image : registry.k8s.io/pause:3.1
隐式约定
这里有一些值得注意的隐式约定:
注意,如果新 Pod 的 topologySpreadConstraints[*].labelSelector 与自身的标签不匹配,将会发生什么。
在上面的例子中,如果移除新 Pod 的标签,则 Pod 仍然可以放置到可用区 B 中的节点上,因为这些约束仍然满足。
然而,在放置之后,集群的不平衡程度保持不变。可用区 A 仍然有 2 个 Pod 带有标签 foo: bar,
而可用区 B 有 1 个 Pod 带有标签 foo: bar。如果这不是你所期望的,
更新工作负载的 topologySpreadConstraints[*].labelSelector 以匹配 Pod 模板中的标签。
集群级别的默认约束
为集群设置默认的拓扑分布约束也是可能的。默认拓扑分布约束在且仅在以下条件满足时才会被应用到 Pod 上:
Pod 没有在其 .spec.topologySpreadConstraints 中定义任何约束。
Pod 隶属于某个 Service、ReplicaSet、StatefulSet 或 ReplicationController。
默认约束可以设置为调度方案 中
PodTopologySpread 插件参数的一部分。约束的设置采用如前所述的 API ,
只是 labelSelector 必须为空。
选择算符是根据 Pod 所属的 Service、ReplicaSet、StatefulSet 或 ReplicationController 来设置的。
配置的示例可能看起来像下面这个样子:
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
pluginConfig :
- name : PodTopologySpread
args :
defaultConstraints :
- maxSkew : 1
topologyKey : topology.kubernetes.io/zone
whenUnsatisfiable : ScheduleAnyway
defaultingType : List
内置默认约束
特性状态: Kubernetes v1.24 [stable]
如果你没有为 Pod 拓扑分布配置任何集群级别的默认约束,
kube-scheduler 的行为就像你指定了以下默认拓扑约束一样:
defaultConstraints :
- maxSkew : 3
topologyKey : "kubernetes.io/hostname"
whenUnsatisfiable : ScheduleAnyway
- maxSkew : 5
topologyKey : "topology.kubernetes.io/zone"
whenUnsatisfiable : ScheduleAnyway
此外,原来用于提供等同行为的 SelectorSpread 插件默认被禁用。
说明:
对于分布约束中所指定的拓扑键而言,PodTopologySpread 插件不会为不包含这些拓扑键的节点评分。
这可能导致在使用默认拓扑约束时,其行为与原来的 SelectorSpread 插件的默认行为不同。
如果你的节点不会同时 设置 kubernetes.io/hostname 和 topology.kubernetes.io/zone 标签,
你应该定义自己的约束而不是使用 Kubernetes 的默认约束。
如果你不想为集群使用默认的 Pod 分布约束,你可以通过设置 defaultingType 参数为 List,
并将 PodTopologySpread 插件配置中的 defaultConstraints 参数置空来禁用默认 Pod 分布约束:
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
pluginConfig :
- name : PodTopologySpread
args :
defaultConstraints : []
defaultingType : List
比较 podAffinity 和 podAntiAffinity
在 Kubernetes 中,
Pod 间亲和性和反亲和性 控制
Pod 彼此的调度方式(更密集或更分散)。
podAffinity吸引 Pod;你可以尝试将任意数量的 Pod 集中到符合条件的拓扑域中。
podAntiAffinity驱逐 Pod。如果将此设为 requiredDuringSchedulingIgnoredDuringExecution 模式,
则只有单个 Pod 可以调度到单个拓扑域;如果你选择 preferredDuringSchedulingIgnoredDuringExecution,
则你将丢失强制执行此约束的能力。
要实现更细粒度的控制,你可以设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本。
这也有助于工作负载的滚动更新和平稳地扩展副本规模。
有关详细信息,请参阅有关 Pod 拓扑分布约束的增强倡议的
动机 一节。
已知局限性
当 Pod 被移除时,无法保证约束仍被满足。例如,缩减某 Deployment 的规模时,Pod 的分布可能不再均衡。
你可以使用 Descheduler 来重新实现 Pod 分布的均衡。
具有污点的节点上匹配的 Pod 也会被统计。
参考 Issue 80921 。
接下来
6 - 污点和容忍度
节点亲和性
是 Pod 的一种属性,它使 Pod
被吸引到一类特定的节点
(这可能出于一种偏好,也可能是硬性要求)。
污点(Taint) 则相反——它使节点能够排斥一类特定的 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。
容忍度允许调度但并不保证调度:作为其功能的一部分,
调度器也会评估其他参数 。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。
每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,
是不会被该节点接受的。
概念
你可以使用命令 kubectl taint
给节点增加一个污点。比如:
kubectl taint nodes node1 key1 = value1:NoSchedule
给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。
这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。
若要移除上述命令所添加的污点,你可以执行:
kubectl taint nodes node1 key1 = value1:NoSchedule-
你可以在 Pod 规约中为 Pod 设置容忍度。
下面两个容忍度均与上面例子中使用 kubectl taint 命令创建的污点相匹配,
因此如果一个 Pod 拥有其中的任何一个容忍度,都能够被调度到 node1:
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
tolerations :
key : "key1"
operator : "Exists"
effect : "NoSchedule"
这里是一个使用了容忍度的 Pod:
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
tolerations :
- key : "example-key"
operator : "Exists"
effect : "NoSchedule"
operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
如果 operator 是 Exists(此时容忍度不能指定 value),或者
如果 operator 是 Equal,则它们的值应该相等。
说明:
存在两种特殊情况:
如果一个容忍度的 key 为空且 operator 为 Exists,
表示这个容忍度与任意的 key、value 和 effect 都匹配,即这个容忍度能容忍任何污点。
如果 effect 为空,则可以与所有键名 key1 的效果相匹配。
上述例子中 effect 使用的值为 NoSchedule,你也可以使用另外一个值 PreferNoSchedule。
effect 字段的允许值包括:
NoExecute这会影响已在节点上运行的 Pod,具体影响如下:
如果 Pod 不能容忍这类污点,会马上被驱逐。
如果 Pod 能够容忍这类污点,但是在容忍度定义中没有指定 tolerationSeconds,
则 Pod 还会一直在这个节点上运行。
如果 Pod 能够容忍这类污点,而且指定了 tolerationSeconds,
则 Pod 还能在这个节点上继续运行这个指定的时间长度。
这段时间过去后,节点生命周期控制器从节点驱除这些 Pod。
NoSchedule除非具有匹配的容忍度规约,否则新的 Pod 不会被调度到带有污点的节点上。
当前正在节点上运行的 Pod 不会 被驱逐。
PreferNoSchedulePreferNoSchedule 是“偏好”或“软性”的 NoSchedule。
控制平面将尝试 避免将不能容忍污点的 Pod 调度到的节点上,但不能保证完全避免。
你可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历,
过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了
Pod 是否会被分配到该节点。需要注意以下情况:
如果未被忽略的污点中存在至少一个 effect 值为 NoSchedule 的污点,
则 Kubernetes 不会将 Pod 调度到该节点。
如果未被忽略的污点中不存在 effect 值为 NoSchedule 的污点,
但是存在至少一个 effect 值为 PreferNoSchedule 的污点,
则 Kubernetes 会尝试 不将 Pod 调度到该节点。
如果未被忽略的污点中存在至少一个 effect 值为 NoExecute 的污点,
则 Kubernetes 不会将 Pod 调度到该节点(如果 Pod 还未在节点上运行),
并且会将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
例如,假设你给一个节点添加了如下污点:
kubectl taint nodes node1 key1 = value1:NoSchedule
kubectl taint nodes node1 key1 = value1:NoExecute
kubectl taint nodes node1 key2 = value2:NoSchedule
假定某个 Pod 有两个容忍度:
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
在这种情况下,上述 Pod 不会被调度到上述节点,因为其没有容忍度和第三个污点相匹配。
但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行,
那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
通常情况下,如果给一个节点添加了一个 effect 值为 NoExecute 的污点,
则任何不能容忍这个污点的 Pod 都会马上被驱逐,任何可以容忍这个污点的 Pod 都不会被驱逐。
但是,如果 Pod 存在一个 effect 值为 NoExecute 的容忍度指定了可选属性
tolerationSeconds 的值,则表示在给节点添加了上述污点之后,
Pod 还能继续在节点上运行的时间。例如,
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
tolerationSeconds : 3600
这表示如果这个 Pod 正在运行,同时一个匹配的污点被添加到其所在的节点,
那么 Pod 还将继续在节点上运行 3600 秒,然后被驱逐。
如果在此之前上述污点被删除了,则 Pod 不会被驱逐。
使用例子
通过污点和容忍度,可以灵活地让 Pod 避开 某些节点或者将 Pod 从某些节点驱逐。
下面是几个使用例子:
专用节点 :如果想将某些节点专门分配给特定的一组用户使用,你可以给这些节点添加一个污点(即,
kubectl taint nodes nodename dedicated=groupName:NoSchedule),
然后给这组用户的 Pod 添加一个相对应的容忍度
(通过编写一个自定义的准入控制器 ,
很容易就能做到)。
拥有上述容忍度的 Pod 就能够被调度到上述专用节点,同时也能够被调度到集群中的其它节点。
如果你希望这些 Pod 只能被调度到上述专用节点,
那么你还需要给这些专用节点另外添加一个和上述污点类似的 label(例如:dedicated=groupName),
同时还要在上述准入控制器中给 Pod 增加节点亲和性要求,要求上述 Pod 只能被调度到添加了
dedicated=groupName 标签的节点上。
配备了特殊硬件的节点 :在部分节点配备了特殊硬件(比如 GPU)的集群中,
我们希望不需要这类硬件的 Pod 不要被调度到这些特殊节点,以便为后继需要这类硬件的 Pod 保留资源。
要达到这个目的,可以先给配备了特殊硬件的节点添加污点
(例如 kubectl taint nodes nodename special=true:NoSchedule 或
kubectl taint nodes nodename special=true:PreferNoSchedule),
然后给使用了这类特殊硬件的 Pod 添加一个相匹配的容忍度。
和专用节点的例子类似,添加这个容忍度的最简单的方法是使用自定义
准入控制器 。
比如,我们推荐使用扩展资源
来表示特殊硬件,给配置了特殊硬件的节点添加污点时包含扩展资源名称,
然后运行一个 ExtendedResourceToleration
准入控制器。此时,因为节点已经被设置污点了,没有对应容忍度的 Pod 不会被调度到这些节点。
但当你创建一个使用了扩展资源的 Pod 时,ExtendedResourceToleration 准入控制器会自动给
Pod 加上正确的容忍度,这样 Pod 就会被自动调度到这些配置了特殊硬件的节点上。
这种方式能够确保配置了特殊硬件的节点专门用于运行需要这些硬件的 Pod,
并且你无需手动给这些 Pod 添加容忍度。
基于污点的驱逐 :这是在每个 Pod 中配置的在节点出现问题时的驱逐行为,
接下来的章节会描述这个特性。
基于污点的驱逐
特性状态: Kubernetes v1.18 [stable]
当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括:
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况 Ready 的值为 "False"。node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况 Ready
的值为 "Unknown"。node.kubernetes.io/memory-pressure:节点存在内存压力。node.kubernetes.io/disk-pressure:节点存在磁盘压力。node.kubernetes.io/pid-pressure:节点的 PID 压力。node.kubernetes.io/network-unavailable:节点网络不可用。node.kubernetes.io/unschedulable:节点不可调度。node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个“外部”云平台驱动,
它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager
的一个控制器初始化这个节点后,kubelet 将删除这个污点。
在节点被排空时,节点控制器或者 kubelet 会添加带有 NoExecute 效果的相关污点。
此效果被默认添加到 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 污点中。
如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。
在某些情况下,当节点不可达时,API 服务器无法与节点上的 kubelet 进行通信。
在与 API 服务器的通信被重新建立之前,删除 Pod 的决定无法传递到 kubelet。
同时,被调度进行删除的那些 Pod 可能会继续运行在分区后的节点上。
说明:
控制面会限制向节点添加新污点的速率。这一速率限制可以管理多个节点同时不可达时
(例如出现网络中断的情况),可能触发的驱逐的数量。
你可以为 Pod 设置 tolerationSeconds,以指定当节点失效或者不响应时,
Pod 维系与该节点间绑定关系的时长。
比如,你可能希望在出现网络分裂事件时,对于一个与节点本地状态有着深度绑定的应用而言,
仍然停留在当前节点上运行一段较长的时间,以等待网络恢复以避免被驱逐。
你为这种 Pod 所设置的容忍度看起来可能是这样:
tolerations :
key : "node.kubernetes.io/unreachable"
operator : "Exists"
effect : "NoExecute"
tolerationSeconds : 6000
说明:
Kubernetes 会自动给 Pod 添加针对 node.kubernetes.io/not-ready 和
node.kubernetes.io/unreachable 的容忍度,且配置 tolerationSeconds=300,
除非用户自身或者某控制器显式设置此容忍度。
这些自动添加的容忍度意味着 Pod 可以在检测到对应的问题之一时,在 5
分钟内保持绑定在该节点上。
DaemonSet 中的 Pod 被创建时,
针对以下污点自动添加的 NoExecute 的容忍度将不会指定 tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
这保证了出现上述问题时 DaemonSet 中的 Pod 永远不会被驱逐。
基于节点状态添加污点
控制平面使用节点控制器 自动创建
与节点状况
对应的、效果为 NoSchedule 的污点。
调度器在进行调度时检查污点,而不是检查节点状况。这确保节点状况不会直接影响调度。
例如,如果 DiskPressure 节点状况处于活跃状态,则控制平面添加
node.kubernetes.io/disk-pressure 污点并且不会调度新的 Pod 到受影响的节点。
如果 MemoryPressure 节点状况处于活跃状态,则控制平面添加
node.kubernetes.io/memory-pressure 污点。
对于新创建的 Pod,可以通过添加相应的 Pod 容忍度来忽略节点状况。
控制平面还在具有除 BestEffort 之外的
QoS 类 的 Pod 上添加
node.kubernetes.io/memory-pressure 容忍度。
这是因为 Kubernetes 将 Guaranteed 或 Burstable QoS 类中的 Pod(甚至没有设置内存请求的 Pod)
视为能够应对内存压力,而新创建的 BestEffort Pod 不会被调度到受影响的节点上。
DaemonSet 控制器自动为所有守护进程添加如下 NoSchedule 容忍度,以防 DaemonSet 崩溃:
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressure(1.14 或更高版本)node.kubernetes.io/unschedulable(1.10 或更高版本)node.kubernetes.io/network-unavailable(只适合主机网络配置 )
添加上述容忍度确保了向后兼容,你也可以选择自由向 DaemonSet 添加容忍度。
接下来
7 - 调度框架
特性状态: Kubernetes v1.19 [stable]
调度框架 是面向 Kubernetes 调度器的一种插件架构,
它由一组直接编译到调度程序中的“插件” API 组成。
这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。
请参考调度框架的设计提案
获取框架设计的更多技术信息。
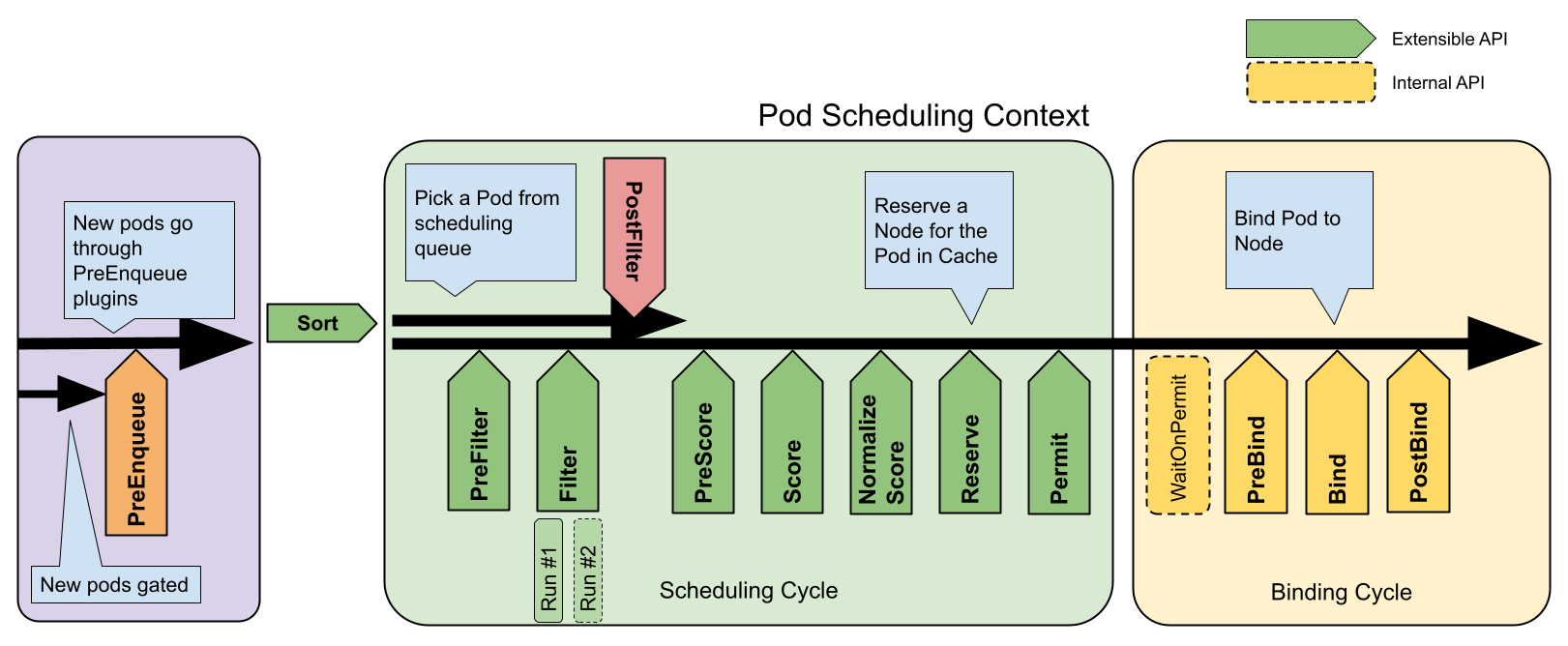
框架工作流程
调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。
这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。
每次调度一个 Pod 的尝试都分为两个阶段,即调度周期 和绑定周期 。
调度周期和绑定周期
调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。
调度周期和绑定周期一起被称为“调度上下文”。
调度周期是串行运行的,而绑定周期可能是同时运行的。
如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期。
Pod 将返回队列并重试。
接口
下图显示了一个 Pod 的调度上下文以及调度框架公开的接口。
一个插件可能实现多个接口,以执行更为复杂或有状态的任务。
某些接口与可以通过调度器配置 来设置的调度器扩展点匹配。
调度框架扩展点
PreEnqueue
这些插件在将 Pod 被添加到内部活动队列之前被调用,在此队列中 Pod 被标记为准备好进行调度。
只有当所有 PreEnqueue 插件返回 Success 时,Pod 才允许进入活动队列。
否则,它将被放置在内部无法调度的 Pod 列表中,并且不会获得 Unschedulable 状态。
要了解有关内部调度器队列如何工作的更多详细信息,请阅读
kube-scheduler 调度队列 。
EnqueueExtension
EnqueueExtension 作为一个接口,插件可以在此接口之上根据集群中的变化来控制是否重新尝试调度被此插件拒绝的
Pod。实现 PreEnqueue、PreFilter、Filter、Reserve 或 Permit 的插件应实现此接口。
QueueingHint
特性状态: Kubernetes v1.28 [beta]
QueueingHint 作为一个回调函数,用于决定是否将 Pod 重新排队到活跃队列或回退队列。
每当集群中发生某种事件或变化时,此函数就会被执行。
当 QueueingHint 发现事件可能使 Pod 可调度时,Pod 将被放入活跃队列或回退队列,
以便调度器可以重新尝试调度 Pod。
说明:
在调度过程中对 QueueingHint 求值是一个 Beta 级别的特性。
v1.28 的系列小版本最初都开启了这个特性的门控;但是发现了内存占用过多的问题,
于是 Kubernetes 项目将该特性门控设置为默认禁用。
在 Kubernetes 的 1.30 版本中,这个特性门控被禁用,你需要手动开启它。
你可以通过 SchedulerQueueingHints
特性门控 来启用它。
队列排序
这些插件用于对调度队列中的 Pod 进行排序。
队列排序插件本质上提供 Less(Pod1, Pod2) 函数。
一次只能启动一个队列插件。
PreFilter
这些插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。
如果 PreFilter 插件返回错误,则调度周期将终止。
Filter
这些插件用于过滤出不能运行该 Pod 的节点。对于每个节点,
调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行,
则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
PostFilter
这些插件在 Filter 阶段后调用,但仅在该 Pod 没有可行的节点时调用。
插件按其配置的顺序调用。如果任何 PostFilter 插件标记节点为 "Schedulable",
则其余的插件不会调用。典型的 PostFilter 实现是抢占,试图通过抢占其他 Pod
的资源使该 Pod 可以调度。
PreScore
这些插件用于执行“前置评分(pre-scoring)”工作,即生成一个可共享状态供 Score 插件使用。
如果 PreScore 插件返回错误,则调度周期将终止。
Score
这些插件用于对通过过滤阶段的节点进行排序。调度器将为每个节点调用每个评分插件。
将有一个定义明确的整数范围,代表最小和最大分数。
在标准化评分 阶段之后,
调度器将根据配置的插件权重合并所有插件的节点分数。
NormalizeScore
这些插件用于在调度器计算 Node 排名之前修改分数。
在此扩展点注册的插件被调用时会使用同一插件的 Score
结果。每个插件在每个调度周期调用一次。
例如,假设一个 BlinkingLightScorer 插件基于具有的闪烁指示灯数量来对节点进行排名。
func ScoreNode (_ * v1.pod, n * v1.Node) (int , error ) {
return getBlinkingLightCount (n)
}
然而,最大的闪烁灯个数值可能比 NodeScoreMax 小。要解决这个问题,
BlinkingLightScorer 插件还应该注册该扩展点。
func NormalizeScores (scores map [string ]int ) {
highest := 0
for _, score := range scores {
highest = max (highest, score)
}
for node, score := range scores {
scores[node] = score* NodeScoreMax/ highest
}
}
如果任何 NormalizeScore 插件返回错误,则调度阶段将终止。
说明:
希望执行“预保留”工作的插件应该使用 NormalizeScore 扩展点。
Reserve
实现了 Reserve 接口的插件,拥有两个方法,即 Reserve 和 Unreserve,
他们分别支持两个名为 Reserve 和 Unreserve 的信息传递性质的调度阶段。
维护运行时状态的插件(又称"有状态插件")应该使用这两个阶段,
以便在节点上的资源被保留和解除保留给特定的 Pod 时,得到调度器的通知。
Reserve 阶段发生在调度器实际将一个 Pod 绑定到其指定节点之前。
它的存在是为了防止在调度器等待绑定成功时发生竞争情况。
每个 Reserve 插件的 Reserve 方法可能成功,也可能失败;
如果一个 Reserve 方法调用失败,后面的插件就不会被执行,Reserve 阶段被认为失败。
如果所有插件的 Reserve 方法都成功了,Reserve 阶段就被认为是成功的,
剩下的调度周期和绑定周期就会被执行。
如果 Reserve 阶段或后续阶段失败了,则触发 Unreserve 阶段。
发生这种情况时,所有 Reserve 插件的 Unreserve 方法将按照
Reserve 方法调用的相反顺序执行。
这个阶段的存在是为了清理与保留的 Pod 相关的状态。
注意:
Reserve 插件中 Unreserve 方法的实现必须是幂等的,并且不能失败。
这个是调度周期的最后一步。
一旦 Pod 处于保留状态,它将在绑定周期结束时触发 Unreserve 插件(失败时)或
PostBind 插件(成功时)。
Permit
Permit 插件在每个 Pod 调度周期的最后调用,用于防止或延迟 Pod 的绑定。
一个允许插件可以做以下三件事之一:
批准
拒绝 Reserve 插件 中的 Unreserve 阶段。
等待 (带有超时)等待 变成拒绝 ,并且 Pod 将返回调度队列,从而触发
Reserve 插件 中的 Unreserve 阶段。
说明:
尽管任何插件可以访问“等待中”状态的 Pod 列表并批准它们
(查看 FrameworkHandlePreBind 阶段。
PreBind
这些插件用于执行 Pod 绑定前所需的所有工作。
例如,一个 PreBind 插件可能需要制备网络卷并且在允许 Pod
运行在该节点之前将其挂载到目标节点上。
如果任何 PreBind 插件返回错误,则 Pod 将被拒绝 并且退回到调度队列中。
Bind
Bind 插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。
各 Bind 插件按照配置顺序被调用。Bind 插件可以选择是否处理指定的 Pod。
如果某 Bind 插件选择处理某 Pod,剩余的 Bind 插件将被跳过 。
PostBind
这是个信息传递性质的接口。
PostBind 插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
插件 API
插件 API 分为两个步骤。首先,插件必须完成注册并配置,然后才能使用扩展点接口。
扩展点接口具有以下形式。
type Plugin interface {
Name () string
}
type QueueSortPlugin interface {
Plugin
Less (* v1.pod, * v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter (context.Context, * framework.CycleState, * v1.pod) error
}
// ...
插件配置
你可以在调度器配置中启用或禁用插件。
如果你在使用 Kubernetes v1.18 或更高版本,
大部分调度插件 都在使用中且默认启用。
除了默认的插件,你还可以实现自己的调度插件并且将它们与默认插件一起配置。
你可以访问 scheduler-plugins
了解更多信息。
如果你正在使用 Kubernetes v1.18 或更高版本,你可以将一组插件设置为一个调度器配置文件,
然后定义不同的配置文件来满足各类工作负载。
了解更多关于多配置文件 。
8 - 动态资源分配
特性状态: Kubernetes v1.27 [alpha]
动态资源分配是一个用于在 Pod 之间和 Pod 内部容器之间请求和共享资源的 API。
它是对为通用资源所提供的持久卷 API 的泛化。第三方资源驱动程序负责跟踪和分配资源。
不同类型的资源支持用任意参数进行定义和初始化。
准备开始
Kubernetes v1.30 包含用于动态资源分配的集群级 API 支持,
但它需要被显式启用 。
你还必须为此 API 要管理的特定资源安装资源驱动程序。
如果你未运行 Kubernetes v1.30,
请查看对应版本的 Kubernetes 文档。
API
resource.k8s.io/v1alpha2
API 组 提供四种类型:
ResourceClass
定义由哪个资源驱动程序处理某种资源,并为其提供通用参数。
集群管理员在安装资源驱动程序时创建 ResourceClass。
ResourceClaim
定义工作负载所需的特定资源实例。
由用户创建(手动管理生命周期,可以在不同的 Pod 之间共享),
或者由控制平面基于 ResourceClaimTemplate 为特定 Pod 创建
(自动管理生命周期,通常仅由一个 Pod 使用)。
ResourceClaimTemplate
定义用于创建 ResourceClaim 的 spec 和一些元数据。
部署工作负载时由用户创建。
PodSchedulingContext
供控制平面和资源驱动程序内部使用,
在需要为 Pod 分配 ResourceClaim 时协调 Pod 调度。
ResourceClass 和 ResourceClaim 的参数存储在单独的对象中,通常使用安装资源驱动程序时创建的
CRD 所定义的类型。
core/v1 的 PodSpec 在 resourceClaims 字段中定义 Pod 所需的 ResourceClaim。
该列表中的条目引用 ResourceClaim 或 ResourceClaimTemplate。
当引用 ResourceClaim 时,使用此 PodSpec 的所有 Pod
(例如 Deployment 或 StatefulSet 中的 Pod)共享相同的 ResourceClaim 实例。
引用 ResourceClaimTemplate 时,每个 Pod 都有自己的实例。
容器资源的 resources.claims 列表定义容器可以访问的资源实例,
从而可以实现在一个或多个容器之间共享资源。
下面是一个虚构的资源驱动程序的示例。
该示例将为此 Pod 创建两个 ResourceClaim 对象,每个容器都可以访问其中一个。
apiVersion : resource.k8s.io/v1alpha2
kind : ResourceClass
name : resource.example.com
driverName : resource-driver.example.com
---
apiVersion : cats.resource.example.com/v1
kind : ClaimParameters
name : large-black-cat-claim-parameters
spec :
color : black
size : large
---
apiVersion : resource.k8s.io/v1alpha2
kind : ResourceClaimTemplate
metadata :
name : large-black-cat-claim-template
spec :
spec :
resourceClassName : resource.example.com
parametersRef :
apiGroup : cats.resource.example.com
kind : ClaimParameters
name : large-black-cat-claim-parameters
apiVersion : v1
kind : Pod
metadata :
name : pod-with-cats
spec :
containers :
- name : container0
image : ubuntu:20.04
command : ["sleep" , "9999" ]
resources :
claims :
- name : cat-0
- name : container1
image : ubuntu:20.04
command : ["sleep" , "9999" ]
resources :
claims :
- name : cat-1
resourceClaims :
- name : cat-0
source :
resourceClaimTemplateName : large-black-cat-claim-template
- name : cat-1
source :
resourceClaimTemplateName : large-black-cat-claim-template
调度
与原生资源(CPU、RAM)和扩展资源(由设备插件管理,并由 kubelet 公布)不同,
调度器不知道集群中有哪些动态资源,
也不知道如何将它们拆分以满足特定 ResourceClaim 的要求。
资源驱动程序负责这些任务。
资源驱动程序在为 ResourceClaim 保留资源后将其标记为“已分配(Allocated)”。
然后告诉调度器集群中可用的 ResourceClaim 的位置。
ResourceClaim 可以在创建时就进行分配(“立即分配”),不用考虑哪些 Pod 将使用它。
默认情况下采用延迟分配,直到需要 ResourceClaim 的 Pod 被调度时
(即“等待第一个消费者”)再进行分配。
在这种模式下,调度器检查 Pod 所需的所有 ResourceClaim,并创建一个 PodScheduling 对象,
通知负责这些 ResourceClaim 的资源驱动程序,告知它们调度器认为适合该 Pod 的节点。
资源驱动程序通过排除没有足够剩余资源的节点来响应调度器。
一旦调度器有了这些信息,它就会选择一个节点,并将该选择存储在 PodScheduling 对象中。
然后,资源驱动程序为分配其 ResourceClaim,以便资源可用于该节点。
完成后,Pod 就会被调度。
作为此过程的一部分,ResourceClaim 会为 Pod 保留。
目前,ResourceClaim 可以由单个 Pod 独占使用或不限数量的多个 Pod 使用。
除非 Pod 的所有资源都已分配和保留,否则 Pod 不会被调度到节点,这是一个重要特性。
这避免了 Pod 被调度到一个节点但无法在那里运行的情况,
这种情况很糟糕,因为被挂起 Pod 也会阻塞为其保留的其他资源,如 RAM 或 CPU。
说明:
由于需要额外的通信,使用 ResourceClaim 的 Pod 的调度将会变慢。
请注意,这也可能会影响不使用 ResourceClaim 的 Pod,因为一次仅调度一个
Pod,在使用 ResourceClaim 处理 Pod 时会进行阻塞 API 调用,
从而推迟调度下一个 Pod。
监控资源
kubelet 提供了一个 gRPC 服务,以便发现正在运行的 Pod 的动态资源。
有关 gRPC 端点的更多信息,请参阅资源分配报告 。
预调度的 Pod
当你(或别的 API 客户端)创建设置了 spec.nodeName 的 Pod 时,调度器将被绕过。
如果 Pod 所需的某个 ResourceClaim 尚不存在、未被分配或未为该 Pod 保留,那么 kubelet
将无法运行该 Pod,并会定期重新检查,因为这些要求可能在以后得到满足。
这种情况也可能发生在 Pod 被调度时调度器中未启用动态资源分配支持的时候(原因可能是版本偏差、配置、特性门控等)。
kube-controller-manager 能够检测到这一点,并尝试通过触发分配和/或预留所需的 ResourceClaim 来使 Pod 可运行。
然而,最好避免这种情况,因为分配给节点的 Pod 会锁住一些正常的资源(RAM、CPU),
而这些资源在 Pod 被卡住时无法用于其他 Pod。为了让一个 Pod 在特定节点上运行,
同时仍然通过正常的调度流程进行,请在创建 Pod 时使用与期望的节点精确匹配的节点选择算符:
apiVersion : v1
kind : Pod
metadata :
name : pod-with-cats
spec :
nodeSelector :
kubernetes.io/hostname : name-of-the-intended-node
...
你还可以在准入时变更传入的 Pod,取消设置 .spec.nodeName 字段,并改为使用节点选择算符。
启用动态资源分配
动态资源分配是一个 Alpha 特性 ,只有在启用 DynamicResourceAllocation
特性门控
和 resource.k8s.io/v1alpha1
API 组 时才启用。
有关详细信息,参阅 --feature-gates 和 --runtime-config
kube-apiserver 参数 。
kube-scheduler、kube-controller-manager 和 kubelet 也需要设置该特性门控。
快速检查 Kubernetes 集群是否支持该功能的方法是列出 ResourceClass 对象:
kubectl get resourceclasses
如果你的集群支持动态资源分配,则响应是 ResourceClass 对象列表或:
No resources found
如果不支持,则会输出如下错误:
error: the server doesn't have a resource type "resourceclasses"
kube-scheduler 的默认配置仅在启用特性门控且使用 v1 配置 API 时才启用 "DynamicResources" 插件。
自定义配置可能需要被修改才能启用它。
除了在集群中启用该功能外,还必须安装资源驱动程序。
欲了解详细信息,请参阅驱动程序的文档。
接下来
9 - 调度器性能调优
特性状态: Kubernetes v1.14 [beta]
作为 kubernetes 集群的默认调度器,
kube-scheduler
主要负责将 Pod 调度到集群的 Node 上。
在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为可调度 Node。
调度器先在集群中找到一个 Pod 的可调度 Node,然后根据一系列函数对这些可调度 Node 打分,
之后选出其中得分最高的 Node 来运行 Pod。
最后,调度器将这个调度决定告知 kube-apiserver,这个过程叫做绑定(Binding) 。
这篇文章将会介绍一些在大规模 Kubernetes 集群下调度器性能优化的方式。
在大规模集群中,你可以调节调度器的表现来平衡调度的延迟(新 Pod 快速就位)
和精度(调度器很少做出糟糕的放置决策)。
你可以通过设置 kube-scheduler 的 percentageOfNodesToScore 来配置这个调优设置。
这个 KubeSchedulerConfiguration 设置决定了调度集群中节点的阈值。
设置阈值
percentageOfNodesToScore 选项接受从 0 到 100 之间的整数值。
0 值比较特殊,表示 kube-scheduler 应该使用其编译后的默认值。
如果你设置 percentageOfNodesToScore 的值超过了 100,
kube-scheduler 的表现等价于设置值为 100。
要修改这个值,先编辑
kube-scheduler 的配置文件 然后重启调度器。
大多数情况下,这个配置文件是 /etc/kubernetes/config/kube-scheduler.yaml。
修改完成后,你可以执行
kubectl get pods -n kube-system | grep kube-scheduler
来检查该 kube-scheduler 组件是否健康。
节点打分阈值
要提升调度性能,kube-scheduler 可以在找到足够的可调度节点之后停止查找。
在大规模集群中,比起考虑每个节点的简单方法相比可以节省时间。
你可以使用整个集群节点总数的百分比作为阈值来指定需要多少节点就足够。
kube-scheduler 会将它转换为节点数的整数值。在调度期间,如果
kube-scheduler 已确认的可调度节点数足以超过了配置的百分比数量,
kube-scheduler 将停止继续查找可调度节点并继续进行
打分阶段 。
调度器如何遍历节点 详细介绍了这个过程。
默认阈值
如果你不指定阈值,Kubernetes 使用线性公式计算出一个比例,在 100-节点集群
下取 50%,在 5000-节点的集群下取 10%。这个自动设置的参数的最低值是 5%。
这意味着,调度器至少会对集群中 5% 的节点进行打分,除非用户将该参数设置的低于 5。
如果你想让调度器对集群内所有节点进行打分,则将 percentageOfNodesToScore 设置为 100。
示例
下面就是一个将 percentageOfNodesToScore 参数设置为 50% 的例子。
apiVersion : kubescheduler.config.k8s.io/v1alpha1
kind : KubeSchedulerConfiguration
algorithmSource :
provider : DefaultProvider
...
percentageOfNodesToScore : 50
调节 percentageOfNodesToScore 参数
percentageOfNodesToScore 的值必须在 1 到 100 之间,而且其默认值是通过集群的规模计算得来的。
另外,还有一个 50 个 Node 的最小值是硬编码在程序中。
说明: 当集群中的可调度节点少于 50 个时,调度器仍然会去检查所有的 Node,
因为可调度节点太少,不足以停止调度器最初的过滤选择。
同理,在小规模集群中,如果你将 percentageOfNodesToScore
设置为一个较低的值,则没有或者只有很小的效果。
如果集群只有几百个节点或者更少,请保持这个配置的默认值。
改变基本不会对调度器的性能有明显的提升。
值得注意的是,该参数设置后可能会导致只有集群中少数节点被选为可调度节点,
很多节点都没有进入到打分阶段。这样就会造成一种后果,
一个本来可以在打分阶段得分很高的节点甚至都不能进入打分阶段。
由于这个原因,这个参数不应该被设置成一个很低的值。
通常的做法是不会将这个参数的值设置的低于 10。
很低的参数值一般在调度器的吞吐量很高且对节点的打分不重要的情况下才使用。
换句话说,只有当你更倾向于在可调度节点中任意选择一个节点来运行这个 Pod 时,
才使用很低的参数设置。
调度器做调度选择的时候如何覆盖所有的 Node
如果你想要理解这一个特性的内部细节,那么请仔细阅读这一章节。
在将 Pod 调度到节点上时,为了让集群中所有节点都有公平的机会去运行这些 Pod,
调度器将会以轮询的方式覆盖全部的 Node。
你可以将 Node 列表想象成一个数组。调度器从数组的头部开始筛选可调度节点,
依次向后直到可调度节点的数量达到 percentageOfNodesToScore 参数的要求。
在对下一个 Pod 进行调度的时候,前一个 Pod 调度筛选停止的 Node 列表的位置,
将会来作为这次调度筛选 Node 开始的位置。
如果集群中的 Node 在多个区域,那么调度器将从不同的区域中轮询 Node,
来确保不同区域的 Node 接受可调度性检查。如下例,考虑两个区域中的六个节点:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
调度器将会按照如下的顺序去评估 Node 的可调度性:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
在评估完所有 Node 后,将会返回到 Node 1,从头开始。
接下来
10 - 资源装箱
在 kube-scheduler 的调度插件
NodeResourcesFit 中存在两种支持资源装箱(bin packing)的策略:MostAllocated 和
RequestedToCapacityRatio。
使用 MostAllocated 策略启用资源装箱
MostAllocated 策略基于资源的利用率来为节点计分,优选分配比率较高的节点。
针对每种资源类型,你可以设置一个权重值以改变其对节点得分的影响。
要为插件 NodeResourcesFit 设置 MostAllocated 策略,
可以使用一个类似于下面这样的调度器配置 :
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
pluginConfig :
- args :
scoringStrategy :
resources :
- name : cpu
weight : 1
- name : memory
weight : 1
- name : intel.com/foo
weight : 3
- name : intel.com/bar
weight : 3
type : MostAllocated
name : NodeResourcesFit
要进一步了解其它参数及其默认配置,请参阅
NodeResourcesFitArgs
使用 RequestedToCapacityRatio 策略来启用资源装箱
RequestedToCapacityRatio 策略允许用户基于请求值与容量的比率,针对参与节点计分的每类资源设置权重。
这一策略使得用户可以使用合适的参数来对扩展资源执行装箱操作,进而提升大规模集群中稀有资源的利用率。
此策略根据所分配资源的一个配置函数来评价节点。
NodeResourcesFit 计分函数中的 RequestedToCapacityRatio 可以通过
scoringStrategy
字段来控制。在 scoringStrategy 字段中,你可以配置两个参数:
requestedToCapacityRatio 和 resources。requestedToCapacityRatio 参数中的 shape
设置使得用户能够调整函数的算法,基于 utilization 和 score 值计算最少请求或最多请求。
resources 参数中包含计分过程中需要考虑的资源的 name,以及用来设置每种资源权重的 weight。
下面是一个配置示例,使用 requestedToCapacityRatio 字段为扩展资源 intel.com/foo
和 intel.com/bar 设置装箱行为:
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
pluginConfig :
- args :
scoringStrategy :
resources :
- name : intel.com/foo
weight : 3
- name : intel.com/bar
weight : 3
requestedToCapacityRatio :
shape :
- utilization : 0
score : 0
- utilization : 100
score : 10
type : RequestedToCapacityRatio
name : NodeResourcesFit
使用 kube-scheduler 标志 --config=/path/to/config/file
引用 KubeSchedulerConfiguration 文件,可以将配置传递给调度器。
要进一步了解其它参数及其默认配置,可以参阅
NodeResourcesFitArgs
调整计分函数
shape 用于指定 RequestedToCapacityRatio 函数的行为。
shape :
- utilization : 0
score : 0
- utilization : 100
score : 10
上面的参数在 utilization 为 0% 时给节点评分为 0,在 utilization 为
100% 时给节点评分为 10,因此启用了装箱行为。
要启用最少请求(least requested)模式,必须按如下方式反转得分值。
shape :
- utilization : 0
score : 10
- utilization : 100
score : 0
resources 是一个可选参数,默认值为:
resources :
- name : cpu
weight : 1
- name : memory
weight : 1
它可以像下面这样用来添加扩展资源:
resources :
- name : intel.com/foo
weight : 5
- name : cpu
weight : 3
- name : memory
weight : 1
weight 参数是可选的,如果未指定,则设置为 1。
同时,weight 不能设置为负值。
节点容量分配的评分
本节适用于希望了解此功能的内部细节的人员。
以下是如何针对给定的一组值来计算节点得分的示例。
请求的资源:
intel.com/foo : 2
memory: 256MB
cpu: 2
资源权重:
intel.com/foo : 5
memory: 1
cpu: 3
FunctionShapePoint {{0, 0}, {100, 10}}
节点 1 配置:
可用:
intel.com/foo: 4
memory: 1 GB
cpu: 8
已用:
intel.com/foo: 1
memory: 256MB
cpu: 1
节点得分:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
节点 2 配置:
可用:
intel.com/foo: 8
memory: 1GB
cpu: 8
已用:
intel.com/foo: 2
memory: 512MB
cpu: 6
节点得分:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
接下来
11 - Pod 优先级和抢占
特性状态: Kubernetes v1.14 [stable]
Pod 可以有优先级 。
优先级表示一个 Pod 相对于其他 Pod 的重要性。
如果一个 Pod 无法被调度,调度程序会尝试抢占(驱逐)较低优先级的 Pod,
以使悬决 Pod 可以被调度。
警告:
在一个并非所有用户都是可信的集群中,恶意用户可能以最高优先级创建 Pod,
导致其他 Pod 被驱逐或者无法被调度。
管理员可以使用 ResourceQuota 来阻止用户创建高优先级的 Pod。
参见默认限制优先级消费 。
如何使用优先级和抢占
要使用优先级和抢占:
新增一个或多个 PriorityClass 。
创建 Pod,并将其 priorityClassNamepriorityClassName 到集合对象(如 Deployment)
的 Pod 模板中。
继续阅读以获取有关这些步骤的更多信息。
说明:
Kubernetes 已经提供了 2 个 PriorityClass:
system-cluster-critical 和 system-node-critical。
这些是常见的类,用于确保始终优先调度关键组件 。
PriorityClass
PriorityClass 是一个无命名空间对象,它定义了从优先级类名称到优先级整数值的映射。
名称在 PriorityClass 对象元数据的 name 字段中指定。
值在必填的 value 字段中指定。值越大,优先级越高。
PriorityClass 对象的名称必须是有效的
DNS 子域名 ,
并且它不能以 system- 为前缀。
PriorityClass 对象可以设置任何小于或等于 10 亿的 32 位整数值。
这意味着 PriorityClass 对象的值范围是从 -2,147,483,648 到 1,000,000,000(含)。
保留更大的数字,用于表示关键系统 Pod 的内置 PriorityClass。
集群管理员应该为这类映射分别创建独立的 PriorityClass 对象。
PriorityClass 还有两个可选字段:globalDefault 和 description。
globalDefault 字段表示这个 PriorityClass 的值应该用于没有 priorityClassName 的 Pod。
系统中只能存在一个 globalDefault 设置为 true 的 PriorityClass。
如果不存在设置了 globalDefault 的 PriorityClass,
则没有 priorityClassName 的 Pod 的优先级为零。
description 字段是一个任意字符串。
它用来告诉集群用户何时应该使用此 PriorityClass。
关于 PodPriority 和现有集群的注意事项
如果你升级一个已经存在的但尚未使用此特性的集群,该集群中已经存在的 Pod 的优先级等效于零。
添加一个将 globalDefault 设置为 true 的 PriorityClass 不会改变现有 Pod 的优先级。
此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。
如果你删除了某个 PriorityClass 对象,则使用被删除的 PriorityClass 名称的现有 Pod 保持不变,
但是你不能再创建使用已删除的 PriorityClass 名称的 Pod。
PriorityClass 示例
apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority
value : 1000000
globalDefault : false
description : "此优先级类应仅用于 XYZ 服务 Pod。"
非抢占式 PriorityClass
特性状态: Kubernetes v1.24 [stable]
配置了 preemptionPolicy: Never 的 Pod 将被放置在调度队列中较低优先级 Pod 之前,
但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源,
它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。
这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试,
从而允许其他优先级较低的 Pod 排在它们之前。
非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
preemptionPolicy 默认为 PreemptLowerPriority,
这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod(现有默认行为也是如此)。
如果 preemptionPolicy 设置为 Never,则该 PriorityClass 中的 Pod 将是非抢占式的。
数据科学工作负载是一个示例用例。用户可以提交他们希望优先于其他工作负载的作业,
但不希望因为抢占运行中的 Pod 而导致现有工作被丢弃。
设置为 preemptionPolicy: Never 的高优先级作业将在其他排队的 Pod 之前被调度,
只要足够的集群资源“自然地”变得可用。
非抢占式 PriorityClass 示例
apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority-nonpreempting
value : 1000000
preemptionPolicy : Never
globalDefault : false
description : "This priority class will not cause other pods to be preempted."
Pod 优先级
在你拥有一个或多个 PriorityClass 对象之后,
你可以创建在其规约中指定这些 PriorityClass 名称之一的 Pod。
优先级准入控制器使用 priorityClassName 字段并填充优先级的整数值。
如果未找到所指定的优先级类,则拒绝 Pod。
以下 YAML 是 Pod 配置的示例,它使用在前面的示例中创建的 PriorityClass。
优先级准入控制器检查 Pod 规约并将其优先级解析为 1000000。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
priorityClassName : high-priority
Pod 优先级对调度顺序的影响
当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序,
并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。
因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。
如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
抢占
Pod 被创建后会进入队列等待调度。
调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。
如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。
让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点,
在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。
如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。
被驱逐的 Pod 消失后,P 可以被调度到该节点上。
当 Pod P 抢占节点 N 上的一个或多个 Pod 时,
Pod P 状态的 nominatedNodeName 字段被设置为节点 N 的名称。
该字段帮助调度程序跟踪为 Pod P 保留的资源,并为用户提供有关其集群中抢占的信息。
请注意,Pod P 不一定会调度到“被提名的节点(Nominated Node)”。
调度程序总是在迭代任何其他节点之前尝试“指定节点”。
在 Pod 因抢占而牺牲时,它们将获得体面终止期。
如果调度程序正在等待牺牲者 Pod 终止时另一个节点变得可用,
则调度程序可以使用另一个节点来调度 Pod P。
因此,Pod 规约中的 nominatedNodeName 和 nodeName 并不总是相同。
此外,如果调度程序抢占节点 N 上的 Pod,但随后比 Pod P 更高优先级的 Pod 到达,
则调度程序可能会将节点 N 分配给新的更高优先级的 Pod。
在这种情况下,调度程序会清除 Pod P 的 nominatedNodeName。
通过这样做,调度程序使 Pod P 有资格抢占另一个节点上的 Pod。
抢占的限制
被抢占牺牲者的体面终止
当 Pod 被抢占时,牺牲者会得到他们的
体面终止期 。
它们可以在体面终止期内完成工作并退出。如果它们不这样做就会被杀死。
这个体面终止期在调度程序抢占 Pod 的时间点和待处理的 Pod (P)
可以在节点 (N) 上调度的时间点之间划分出了一个时间跨度。
同时,调度器会继续调度其他待处理的 Pod。当牺牲者退出或被终止时,
调度程序会尝试在待处理队列中调度 Pod。
因此,调度器抢占牺牲者的时间点与 Pod P 被调度的时间点之间通常存在时间间隔。
为了最小化这个差距,可以将低优先级 Pod 的体面终止时间设置为零或一个小数字。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget
(PDB) 允许多副本应用程序的所有者限制因自愿性质的干扰而同时终止的 Pod 数量。
Kubernetes 在抢占 Pod 时支持 PDB,但对 PDB 的支持是基于尽力而为原则的。
调度器会尝试寻找不会因被抢占而违反 PDB 的牺牲者,但如果没有找到这样的牺牲者,
抢占仍然会发生,并且即使违反了 PDB 约束也会删除优先级较低的 Pod。
与低优先级 Pod 之间的 Pod 间亲和性
只有当这个问题的答案是肯定的时,才考虑在一个节点上执行抢占操作:
“如果从此节点上删除优先级低于悬决 Pod 的所有 Pod,悬决 Pod 是否可以在该节点上调度?”
说明:
抢占并不一定会删除所有较低优先级的 Pod。
如果悬决 Pod 可以通过删除少于所有较低优先级的 Pod 来调度,
那么只有一部分较低优先级的 Pod 会被删除。
即便如此,上述问题的答案必须是肯定的。
如果答案是否定的,则不考虑在该节点上执行抢占。
如果悬决 Pod 与节点上的一个或多个较低优先级 Pod 具有 Pod 间亲和性 ,
则在没有这些较低优先级 Pod 的情况下,无法满足 Pod 间亲和性规则。
在这种情况下,调度程序不会抢占节点上的任何 Pod。
相反,它寻找另一个节点。调度程序可能会找到合适的节点,
也可能不会。无法保证悬决 Pod 可以被调度。
我们针对此问题推荐的解决方案是仅针对同等或更高优先级的 Pod 设置 Pod 间亲和性。
跨节点抢占
假设正在考虑在一个节点 N 上执行抢占,以便可以在 N 上调度待处理的 Pod P。
只有当另一个节点上的 Pod 被抢占时,P 才可能在 N 上变得可行。
下面是一个例子:
调度器正在考虑将 Pod P 调度到节点 N 上。
Pod Q 正在与节点 N 位于同一区域的另一个节点上运行。
Pod P 与 Pod Q 具有 Zone 维度的反亲和(topologyKey:topology.kubernetes.io/zone)设置。
Pod P 与 Zone 中的其他 Pod 之间没有其他反亲和性设置。
为了在节点 N 上调度 Pod P,可以抢占 Pod Q,但调度器不会进行跨节点抢占。
因此,Pod P 将被视为在节点 N 上不可调度。
如果将 Pod Q 从所在节点中移除,则不会违反 Pod 间反亲和性约束,
并且 Pod P 可能会被调度到节点 N 上。
如果有足够的需求,并且如果我们找到性能合理的算法,
我们可能会考虑在未来版本中添加跨节点抢占。
故障排除
Pod 优先级和抢占可能会产生不必要的副作用。以下是一些潜在问题的示例以及处理这些问题的方法。
Pod 被不必要地抢占
抢占在资源压力较大时从集群中删除现有 Pod,为更高优先级的悬决 Pod 腾出空间。
如果你错误地为某些 Pod 设置了高优先级,这些无意的高优先级 Pod 可能会导致集群中出现抢占行为。
Pod 优先级是通过设置 Pod 规约中的 priorityClassName 字段来指定的。
优先级的整数值然后被解析并填充到 podSpec 的 priority 字段。
为了解决这个问题,你可以将这些 Pod 的 priorityClassName 更改为使用较低优先级的类,
或者将该字段留空。默认情况下,空的 priorityClassName 解析为零。
当 Pod 被抢占时,集群会为被抢占的 Pod 记录事件。只有当集群没有足够的资源用于 Pod 时,
才会发生抢占。在这种情况下,只有当悬决 Pod(抢占者)的优先级高于受害 Pod 时才会发生抢占。
当没有悬决 Pod,或者悬决 Pod 的优先级等于或低于牺牲者时,不得发生抢占。
如果在这种情况下发生抢占,请提出问题。
有 Pod 被抢占,但抢占者并没有被调度
当 Pod 被抢占时,它们会收到请求的体面终止期,默认为 30 秒。
如果受害 Pod 在此期限内没有终止,它们将被强制终止。
一旦所有牺牲者都离开,就可以调度抢占者 Pod。
在抢占者 Pod 等待牺牲者离开的同时,可能某个适合同一个节点的更高优先级的 Pod 被创建。
在这种情况下,调度器将调度优先级更高的 Pod 而不是抢占者。
这是预期的行为:具有较高优先级的 Pod 应该取代具有较低优先级的 Pod。
优先级较高的 Pod 在优先级较低的 Pod 之前被抢占
调度程序尝试查找可以运行悬决 Pod 的节点。如果没有找到这样的节点,
调度程序会尝试从任意节点中删除优先级较低的 Pod,以便为悬决 Pod 腾出空间。
如果具有低优先级 Pod 的节点无法运行悬决 Pod,
调度器可能会选择另一个具有更高优先级 Pod 的节点(与其他节点上的 Pod 相比)进行抢占。
牺牲者的优先级必须仍然低于抢占者 Pod。
当有多个节点可供执行抢占操作时,调度器会尝试选择具有一组优先级最低的 Pod 的节点。
但是,如果此类 Pod 具有 PodDisruptionBudget,当它们被抢占时,
则会违反 PodDisruptionBudget,那么调度程序可能会选择另一个具有更高优先级 Pod 的节点。
当存在多个节点抢占且上述场景均不适用时,调度器会选择优先级最低的节点。
Pod 优先级和服务质量之间的相互作用
Pod 优先级和 QoS 类
是两个正交特征,交互很少,并且对基于 QoS 类设置 Pod 的优先级没有默认限制。
调度器的抢占逻辑在选择抢占目标时不考虑 QoS。
抢占会考虑 Pod 优先级并尝试选择一组优先级最低的目标。
仅当移除优先级最低的 Pod 不足以让调度程序调度抢占式 Pod,
或者最低优先级的 Pod 受 PodDisruptionBudget 保护时,才会考虑优先级较高的 Pod。
kubelet 使用优先级来确定
节点压力驱逐 Pod 的顺序。
你可以使用 QoS 类来估计 Pod 最有可能被驱逐的顺序。kubelet 根据以下因素对 Pod 进行驱逐排名:
对紧俏资源的使用是否超过请求值
Pod 优先级
相对于请求的资源使用量
有关更多详细信息,请参阅
kubelet 驱逐时 Pod 的选择 。
当某 Pod 的资源用量未超过其请求时,kubelet 节点压力驱逐不会驱逐该 Pod。
如果优先级较低的 Pod 的资源使用量没有超过其请求,则不会被驱逐。
另一个优先级较高且资源使用量超过其请求的 Pod 可能会被驱逐。
接下来
12 - 节点压力驱逐
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet
监控集群节点的内存、磁盘空间和文件系统的 inode 等资源。
当这些资源中的一个或者多个达到特定的消耗水平,
kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
在节点压力驱逐期间,kubelet 将所选 Pod 的阶段
设置为 Failed 并终止 Pod。
节点压力驱逐不同于 API 发起的驱逐 。
kubelet 并不理会你配置的 PodDisruptionBudget
或者是 Pod 的 terminationGracePeriodSeconds。
如果你使用了软驱逐条件 ,kubelet 会考虑你所配置的
eviction-max-pod-grace-period。
如果你使用了硬驱逐条件 ,kubelet 使用 0s
宽限期(立即关闭)来终止 Pod。
自我修复行为
kubelet 在终止最终用户 Pod 之前会尝试回收节点级资源 。
例如,它会在磁盘资源不足时删除未使用的容器镜像。
如果 Pod 是由替换失败 Pod 的工作负载 资源
(例如 StatefulSet
或者 Deployment )管理,
则控制平面或 kube-controller-manager 会创建新的 Pod 来代替被驱逐的 Pod。
静态 Pod 的自我修复
如果你在面临资源压力的节点上运行静态 Pod,则 kubelet 可能会驱逐该静态 Pod。
由于静态 Pod 始终表示在该节点上运行 Pod 的意图,kubelet 会尝试创建替代 Pod。
创建替代 Pod 时,kubelet 会考虑静态 Pod 的优先级。如果静态 Pod 清单指定了低优先级,
并且集群的控制平面内定义了优先级更高的 Pod,并且节点面临资源压力,则 kubelet
可能无法为该静态 Pod 腾出空间。
即使节点上存在资源压力,kubelet 也会继续尝试运行所有静态 pod。
驱逐信号和阈值
kubelet 使用各种参数来做出驱逐决定,如下所示:
驱逐信号
驱逐信号是特定资源在特定时间点的当前状态。
kubelet 使用驱逐信号,通过将信号与驱逐条件进行比较来做出驱逐决定,
驱逐条件是节点上应该可用资源的最小量。
Linux 系统中,kubelet 使用以下驱逐信号:
驱逐信号
描述
memory.availablememory.available := node.status.capacity[memory] - node.stats.memory.workingSet
nodefs.availablenodefs.available := node.stats.fs.available
nodefs.inodesFreenodefs.inodesFree := node.stats.fs.inodesFree
imagefs.availableimagefs.available := node.stats.runtime.imagefs.available
imagefs.inodesFreeimagefs.inodesFree := node.stats.runtime.imagefs.inodesFree
pid.availablepid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc
在上表中,描述 列显示了 kubelet 如何获取信号的值。每个信号支持百分比值或者是字面值。
kubelet 计算相对于与信号有关的总量的百分比值。
memory.available 的值来自 cgroupfs,而不是像 free -m 这样的工具。
这很重要,因为 free -m 在容器中不起作用,如果用户使用
节点可分配资源
这一功能特性,资源不足的判定是基于 cgroup 层次结构中的用户 Pod 所处的局部及 cgroup 根节点作出的。
这个脚本 或者
cgroupv2 脚本
重现了 kubelet 为计算 memory.available 而执行的相同步骤。
kubelet 在其计算中排除了 inactive_file(非活动 LRU 列表上基于文件来虚拟的内存的字节数),
因为它假定在压力下内存是可回收的。
kubelet 可识别以下两个特定的文件系统标识符:
nodefs:节点的主要文件系统,用于本地磁盘卷、不受内存支持的 emptyDir 卷、日志存储等。
例如,nodefs 包含 /var/lib/kubelet/。imagefs:可选文件系统,供容器运行时存储容器镜像和容器可写层。
kubelet 会自动发现这些文件系统并忽略节点本地的其它文件系统。kubelet 不支持其他配置。
一些 kubelet 垃圾收集功能已被弃用,以鼓励使用驱逐机制。
现有标志
原因
--maximum-dead-containers一旦旧的日志存储在容器的上下文之外就会被弃用
--maximum-dead-containers-per-container一旦旧的日志存储在容器的上下文之外就会被弃用
--minimum-container-ttl-duration一旦旧的日志存储在容器的上下文之外就会被弃用
驱逐条件
你可以为 kubelet 指定自定义驱逐条件,以便在作出驱逐决定时使用。
你可以设置软性的 和硬性的 驱逐阈值。
驱逐条件的形式为 [eviction-signal][operator][quantity],其中:
eviction-signal 是要使用的驱逐信号 。operator 是你想要的关系运算符 ,
比如 <(小于)。quantity 是驱逐条件数量,例如 1Gi。
quantity 的值必须与 Kubernetes 使用的数量表示相匹配。
你可以使用文字值或百分比(%)。
例如,如果一个节点的总内存为 10GiB 并且你希望在可用内存低于 1GiB 时触发驱逐,
则可以将驱逐条件定义为 memory.available<10% 或
memory.available< 1G(你不能同时使用二者)。
你可以配置软和硬驱逐条件。
软驱逐条件
软驱逐条件将驱逐条件与管理员所必须指定的宽限期配对。
在超过宽限期之前,kubelet 不会驱逐 Pod。
如果没有指定的宽限期,kubelet 会在启动时返回错误。
你可以既指定软驱逐条件宽限期,又指定 Pod 终止宽限期的上限,给 kubelet 在驱逐期间使用。
如果你指定了宽限期的上限并且 Pod 满足软驱逐阈条件,则 kubelet 将使用两个宽限期中的较小者。
如果你没有指定宽限期上限,kubelet 会立即杀死被驱逐的 Pod,不允许其体面终止。
你可以使用以下标志来配置软驱逐条件:
eviction-soft:一组驱逐条件,如 memory.available<1.5Gi,
如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。eviction-soft-grace-period:一组驱逐宽限期,
如 memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。eviction-max-pod-grace-period:在满足软驱逐条件而终止 Pod 时使用的最大允许宽限期(以秒为单位)。
硬驱逐条件
硬驱逐条件没有宽限期。当达到硬驱逐条件时,
kubelet 会立即杀死 pod,而不会正常终止以回收紧缺的资源。
你可以使用 eviction-hard 标志来配置一组硬驱逐条件,
例如 memory.available<1Gi。
kubelet 具有以下默认硬驱逐条件:
memory.available<100Minodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linux 节点)
只有在没有更改任何参数的情况下,硬驱逐阈值才会被设置成这些默认值。
如果你更改了任何参数的值,则其他参数的取值不会继承其默认值设置,而将被设置为零。
为了提供自定义值,你应该分别设置所有阈值。
驱逐监测间隔
kubelet 根据其配置的 housekeeping-interval(默认为 10s)评估驱逐条件。
节点状况
kubelet 报告节点状况 以反映节点处于压力之下,
原因是满足硬性的或软性的驱逐条件,与配置的宽限期无关。
kubelet 根据下表将驱逐信号映射为节点状况:
节点条件
驱逐信号
描述
MemoryPressurememory.available节点上的可用内存已满足驱逐条件
DiskPressurenodefs.available、nodefs.inodesFree、imagefs.available 或 imagefs.inodesFree节点的根文件系统或镜像文件系统上的可用磁盘空间和 inode 已满足驱逐条件
PIDPressurepid.available(Linux) 节点上的可用进程标识符已低于驱逐条件
控制平面还将这些节点状况映射 为其污点。
kubelet 根据配置的 --node-status-update-frequency 更新节点条件,默认为 10s。
节点状况波动
在某些情况下,节点在软驱逐条件上下振荡,而没有保持定义的宽限期。
这会导致报告的节点条件在 true 和 false 之间不断切换,从而导致错误的驱逐决策。
为了防止振荡,你可以使用 eviction-pressure-transition-period 标志,
该标志控制 kubelet 在将节点条件转换为不同状态之前必须等待的时间。
过渡期的默认值为 5m。
回收节点级资源
kubelet 在驱逐最终用户 Pod 之前会先尝试回收节点级资源。
当报告 DiskPressure 节点状况时,kubelet 会根据节点上的文件系统回收节点级资源。
有 imagefs
如果节点有一个专用的 imagefs 文件系统供容器运行时使用,kubelet 会执行以下操作:
如果 nodefs 文件系统满足驱逐条件,kubelet 垃圾收集死亡 Pod 和容器。
如果 imagefs 文件系统满足驱逐条件,kubelet 将删除所有未使用的镜像。
没有 imagefs
如果节点只有一个满足驱逐条件的 nodefs 文件系统,
kubelet 按以下顺序释放磁盘空间:
对死亡的 Pod 和容器进行垃圾收集
删除未使用的镜像
kubelet 驱逐时 Pod 的选择
如果 kubelet 回收节点级资源的尝试没有使驱逐信号低于条件,
则 kubelet 开始驱逐最终用户 Pod。
kubelet 使用以下参数来确定 Pod 驱逐顺序:
Pod 的资源使用是否超过其请求
Pod 优先级 Pod 相对于请求的资源使用情况
因此,kubelet 按以下顺序排列和驱逐 Pod:
首先考虑资源使用量超过其请求的 BestEffort 或 Burstable Pod。
这些 Pod 会根据它们的优先级以及它们的资源使用级别超过其请求的程度被逐出。
资源使用量少于请求量的 Guaranteed Pod 和 Burstable Pod 根据其优先级被最后驱逐。
说明:
kubelet 不使用 Pod 的 QoS 类 来确定驱逐顺序。
在回收内存等资源时,你可以使用 QoS 类来估计最可能的 Pod 驱逐顺序。
QoS 分类不适用于临时存储(EphemeralStorage)请求,
因此如果节点在 DiskPressure 下,则上述场景将不适用。
仅当 Guaranteed Pod 中所有容器都被指定了请求和限制并且二者相等时,才保证 Pod 不被驱逐。
这些 Pod 永远不会因为另一个 Pod 的资源消耗而被驱逐。
如果系统守护进程(例如 kubelet 和 journald)
消耗的资源比通过 system-reserved 或 kube-reserved 分配保留的资源多,
并且该节点只有 Guaranteed 或 Burstable Pod 使用的资源少于其上剩余的请求,
那么 kubelet 必须选择驱逐这些 Pod 中的一个以保持节点稳定性并减少资源匮乏对其他 Pod 的影响。
在这种情况下,它会选择首先驱逐最低优先级的 Pod。
如果你正在运行静态 Pod
并且希望避免其在资源压力下被驱逐,请直接为该 Pod 设置 priority 字段。
静态 Pod 不支持 priorityClassName 字段。
当 kubelet 因 inode 或 进程 ID 不足而驱逐 Pod 时,
它使用 Pod 的相对优先级来确定驱逐顺序,因为 inode 和 PID 没有对应的请求字段。
kubelet 根据节点是否具有专用的 imagefs 文件系统对 Pod 进行不同的排序:
有 imagefs
如果 nodefs 触发驱逐,
kubelet 会根据 nodefs 使用情况(本地卷 + 所有容器的日志)对 Pod 进行排序。
如果 imagefs 触发驱逐,kubelet 会根据所有容器的可写层使用情况对 Pod 进行排序。
没有 imagefs
如果 nodefs 触发驱逐,
kubelet 会根据磁盘总用量(本地卷 + 日志和所有容器的可写层)对 Pod 进行排序。
最小驱逐回收
在某些情况下,驱逐 Pod 只会回收少量的紧俏资源。
这可能导致 kubelet 反复达到配置的驱逐条件并触发多次驱逐。
你可以使用 --eviction-minimum-reclaim 标志或
kubelet 配置文件
为每个资源配置最小回收量。
当 kubelet 注意到某个资源耗尽时,它会继续回收该资源,直到回收到你所指定的数量为止。
例如,以下配置设置最小回收量:
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
evictionHard :
memory.available : "500Mi"
nodefs.available : "1Gi"
imagefs.available : "100Gi"
evictionMinimumReclaim :
memory.available : "0Mi"
nodefs.available : "500Mi"
imagefs.available : "2Gi"
在这个例子中,如果 nodefs.available 信号满足驱逐条件,
kubelet 会回收资源,直到信号达到 1GiB 的条件,
然后继续回收至少 500MiB 直到信号达到 1.5GiB。
类似地,kubelet 尝试回收 imagefs 资源,直到 imagefs.available 值达到 102Gi,
即 102 GiB 的可用容器镜像存储。如果 kubelet 可以回收的存储量小于 2GiB,
则 kubelet 不会回收任何内容。
对于所有资源,默认的 eviction-minimum-reclaim 为 0。
节点内存不足行为
如果节点在 kubelet 能够回收内存之前遇到内存不足 (OOM)事件,
则节点依赖 oom_killer 来响应。
kubelet 根据 Pod 的服务质量(QoS)为每个容器设置一个 oom_score_adj 值。
服务质量
oom_score_adj
Guaranteed-997
BestEffort1000
Burstablemin(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999)
说明:
kubelet 还将具有 system-node-critical
优先级
的任何 Pod 中的容器 oom_score_adj 值设为 -997。
如果 kubelet 在节点遇到 OOM 之前无法回收内存,
则 oom_killer 根据它在节点上使用的内存百分比计算 oom_score,
然后加上 oom_score_adj 得到每个容器有效的 oom_score。
然后它会杀死得分最高的容器。
这意味着低 QoS Pod 中相对于其调度请求消耗内存较多的容器,将首先被杀死。
与 Pod 驱逐不同,如果容器被 OOM 杀死,
kubelet 可以根据其 restartPolicy 重新启动它。
良好实践
以下各小节阐述驱逐配置的好的做法。
可调度的资源和驱逐策略
当你为 kubelet 配置驱逐策略时,
你应该确保调度程序不会在 Pod 触发驱逐时对其进行调度,因为这类 Pod 会立即引起内存压力。
考虑以下场景:
节点内存容量:10GiB
操作员希望为系统守护进程(内核、kubelet 等)保留 10% 的内存容量
操作员希望在节点内存利用率达到 95% 以上时驱逐 Pod,以减少系统 OOM 的概率。
为此,kubelet 启动设置如下:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
在此配置中,--system-reserved 标志为系统预留了 1GiB 的内存,
即 总内存的 10% + 驱逐条件量。
如果 Pod 使用的内存超过其请求值或者系统使用的内存超过 1Gi,
则节点可以达到驱逐条件,这使得 memory.available 信号低于 500MiB 并触发条件。
DaemonSets 和节点压力驱逐
Pod 优先级是做出驱逐决定的主要因素。
如果你不希望 kubelet 驱逐属于 DaemonSet 的 Pod,
请在 Pod 规约中通过指定合适的 priorityClassName 为这些 Pod
提供足够高的 priorityClass。
你还可以使用较低优先级或默认优先级,以便
仅在有足够资源时才运行 DaemonSet Pod。
已知问题
以下部分描述了与资源不足处理相关的已知问题。
kubelet 可能不会立即观察到内存压力
默认情况下,kubelet 轮询 cAdvisor 以定期收集内存使用情况统计信息。
如果该轮询时间窗口内内存使用量迅速增加,kubelet 可能无法足够快地观察到 MemoryPressure,
但是 OOM killer 仍将被调用。
你可以使用 --kernel-memcg-notification
标志在 kubelet 上启用 memcg 通知 API,以便在超过条件时立即收到通知。
如果你不是追求极端利用率,而是要采取合理的过量使用措施,
则解决此问题的可行方法是使用 --kube-reserved 和 --system-reserved 标志为系统分配内存。
active_file 内存未被视为可用内存
在 Linux 上,内核跟踪活动最近最少使用(LRU)列表上的基于文件所虚拟的内存字节数作为 active_file 统计信息。
kubelet 将 active_file 内存区域视为不可回收。
对于大量使用块设备形式的本地存储(包括临时本地存储)的工作负载,
文件和块数据的内核级缓存意味着许多最近访问的缓存页面可能被计为 active_file。
如果这些内核块缓冲区中在活动 LRU 列表上有足够多,
kubelet 很容易将其视为资源用量过量并为节点设置内存压力污点,从而触发 Pod 驱逐。
更多细节请参见 https://github.com/kubernetes/kubernetes/issues/43916 。
你可以通过为可能执行 I/O 密集型活动的容器设置相同的内存限制和内存请求来应对该行为。
你将需要估计或测量该容器的最佳内存限制值。
接下来
13 - API 发起的驱逐
API 发起的驱逐是一个先调用
Eviction API
创建 Eviction 对象,再由该对象体面地中止 Pod 的过程。
你可以通过直接调用 Eviction API 发起驱逐,也可以通过编程的方式使用
API 服务器 的客户端来发起驱逐,
比如 kubectl drain 命令。
此操作创建一个 Eviction 对象,该对象再驱动 API 服务器终止选定的 Pod。
API 发起的驱逐将遵从你的
PodDisruptionBudgetsterminationGracePeriodSeconds
使用 API 创建 Eviction 对象,就像对 Pod 执行策略控制的
DELETE 操作
调用 Eviction API
你可以使用 Kubernetes 语言客户端
来访问 Kubernetes API 并创建 Eviction 对象。
要执行此操作,你应该用 POST 发出要尝试的请求,类似于下面的示例:
说明:
policy/v1 版本的 Eviction 在 v1.22 以及更高的版本中可用,之前的发行版本使用 policy/v1beta1 版本。
{
"apiVersion" : "policy/v1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
说明:
在 v1.22 版本废弃以支持 policy/v1。
{
"apiVersion" : "policy/v1beta1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
或者,你可以通过使用 curl 或者 wget 来访问 API 以尝试驱逐操作,类似于以下示例:
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
API 发起驱逐的工作原理
当你使用 API 来请求驱逐时,API 服务器将执行准入检查,并通过以下方式之一做出响应:
200 OK:允许驱逐,子资源 Eviction 被创建,并且 Pod 被删除,
类似于发送一个 DELETE 请求到 Pod 地址。429 Too Many Requests:当前不允许驱逐,因为配置了
PodDisruptionBudget 。
你可以稍后再尝试驱逐。你也可能因为 API 速率限制而看到这种响应。500 Internal Server Error:不允许驱逐,因为存在配置错误,
例如存在多个 PodDisruptionBudgets 引用同一个 Pod。
如果你想驱逐的 Pod 不属于有 PodDisruptionBudget 的工作负载,
API 服务器总是返回 200 OK 并且允许驱逐。
如果 API 服务器允许驱逐,Pod 按照如下方式删除:
API 服务器中的 Pod 资源会更新上删除时间戳,之后 API 服务器会认为此 Pod 资源将被终止。
此 Pod 资源还会标记上配置的宽限期。
本地运行状态的 Pod 所处的节点上的 kubelet
注意到 Pod 资源被标记为终止,并开始优雅停止本地 Pod。
当 kubelet 停止 Pod 时,控制面从 Endpoint
和 EndpointSlice
对象中移除该 Pod。因此,控制器不再将此 Pod 视为有用对象。
Pod 的宽限期到期后,kubelet 强制终止本地 Pod。
kubelet 告诉 API 服务器删除 Pod 资源。
API 服务器删除 Pod 资源。
解决驱逐被卡住的问题
在某些情况下,你的应用可能进入中断状态,
在你干预之前,驱逐 API 总是返回 429 或 500。
例如,如果 ReplicaSet 为你的应用程序创建了 Pod,
但新的 Pod 没有进入 Ready 状态,就会发生这种情况。
在最后一个被驱逐的 Pod 有很长的终止宽限期的情况下,你可能也会注意到这种行为。
如果你注意到驱逐被卡住,请尝试以下解决方案之一:
终止或暂停导致问题的自动化操作,重新启动操作之前,请检查被卡住的应用程序。
等待一段时间后,直接从集群控制平面删除 Pod,而不是使用 Eviction API。
接下来